最近更新于 2024-05-05 14:18
测试环境:
Windows 11 专业工作站版 22H2
Visual Studio 2022 专业版
Windows 下中文使用的 GBK 编码,每个汉字占用 2 字节,而在微软的 MSVC 编译器中对于 char 的实现目前是 1 字节(至少我接触到的编译器目前都是 1 字节,比如还有 GNU gcc/g++,标准规定的是至少 1字节,见下图)。

所以存储汉字的时候每两个字节才是一个字。如果使用 wchar_t 的话,可以将两个字节视为一个字(注意 GNU gcc/g++ 中 wchar_t 默认是 4 个字节)。但是使用 wchar_t 的时候,标准库的输出函数很大可能会遇到无法输出的问题。
#include <stdio.h>
#include <Windows.h>
int main()
{
// 字符
const char *str = "ABC 你好啊\n";
printf("%s", str);
// 宽字符
const wchar_t *wstr = L"ABC 你好啊\n";
wprintf(L"%s", wstr); // 标准库的宽字符打印函数
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), wstr, wcslen(wstr), NULL, NULL); // Windows API 打印函数
}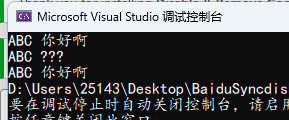
这里可以使用 Windows API 提供的 WriteConsole 函数进行打印,就能正常输出。第一个参数传标准输出的句柄,第二个参数传入要打印的字符串,第三个传字符串长度,后面的 NULL 就行。
第一个参数的句柄类似于 Linux 的文件描述符,在控制台使用时有标准输入句柄、标准输出句柄和标准错误句柄,对应 Linux 下终端使用时的标准输入文件描述符、标注输出文件描述符和标准错误文件描述符。
这个句柄(或文件描述符)就对应着 Windows 控制台(或 Linux 终端)的输出输入,要显示什么就使用标准输出,要从控制台(或终端)读取就使用标准输入句柄(或标准输入文件描述符),打印错误信息就使用标准错误。
Linux 下的标准错误记得是无缓冲输出,可以直接输出到终端,而标准输出则是先放到缓冲区,在满足一定条件时才刷新到终端,比如换行符,缓冲区满了以及程序正常结束。估计着 Windows 的这个也差不多吧,我是才开始学习 Windows API,还不是很了解机制,现在也是边学边记录一些。