最近更新于 2025-01-06 10:48
Acrobat 默认打开 PDF 会自动尝试对内容进行识别,除非本身内容排版比较规则,否则识别后效果很糟。另外,一打开就卡在识别操作,导致不能立即做别的操作。
如果排版复杂(图案和内容重叠、存在倾斜角度等),识别效果就很烂了,而且这个识别操作后可能会改变 PDF。比如纯图像的 PDF 转成文本可编辑的,要是排版没识别对,就把页面排版搞得一团糟。
我用 Acrobat 打开 PDF 不一定是要编辑内容,至少我大部分时候都不是为了编辑内容(一般也就是文档拼接、扫描件的锐化和去背景),也不需要去识别。要是 PDF 页数多一点,那识别用的时长就挺感人,打开后就一直要等着它识别,识别完了才能进行其它操作。识别是可以手动触发的,不用就不需要自动识别。
用 Acrobat 任意打开一个 PDF 文档,点“编辑 PDF”工具
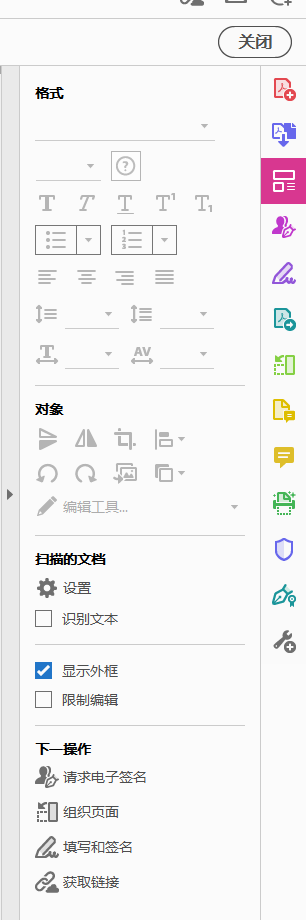
可以看到在“扫描的文档”下有一个“识别文本”的选项,去除勾选后就不会自动识别
Adobe Acrobat Pro 2024 关闭自动识别文本