最近更新于 2025-05-18 16:50
1 前言
第一次玩 Stable Diffusion WebUI 是三十几天前,当时还在用四年半前(大学前暑假)买的轻薄本,而在半年前独显还坏了,所以是纯纯的用 CPU 折腾,刚开始纯 CPU 跑,后面发现 OpenVINO 有个 fork 版本支持 Intel 核显。一张 512×768 的图(不用高清放大),纯 CPU 能跑个 1 小时左右吧,核显能跑五六分钟。
虽然核显提速明显,但是整体速度也不是很快,这个还是其次的。主要是 OpenVINO 版不完善,而且我看 GitHub 的提交记录而稀少,更新不积极,应该不怎么重视吧(到目前为止显示最近的更新已经是两个月以上了)。其中的不完善体现在多个方面:①核显加速是通过脚本实现的,也就是使用了核显加速就不能使用其它自定义脚本了;②核显加速对内存依赖非常高,当时我为了尝试更大的图,把内存从 20G (4+16)改到 36G(4+32),然而我测试的极限大概也只能画到 750×1000 左右,再大就会报错说什么内存地址错误之类的,盯着任务管理器看就会发现在某个时候突然内存跑满,然后终端就出现报错,也就是说内存爆了;③核显加速支持范围太小,只能在文生图和图生图使用,且文生图中不能使用高清化,一旦开了就会变成 CPU 跑,然后第三方插件没发现有支持的,比如常用 ControlNet 等等。在一系列的原因之下,最后我放弃了。
前几天我买了台新的笔记本电脑,RTX4060 的显卡,24 号下午到了,先是测试了一番,又把系统换成专业版,接着装各种软件,晚上把 WebUI 配上了,当时试了一下,还是画 512×768 的图,仅仅几秒就画出来了,有了前面用 CPU 折腾的体验,这速度快得让人挺兴奋的。
配置 WebUI 其实挺简单的,电脑的显卡驱动保证安装好了,安装 Python 和 Git,再克隆 WebUI 的源码下来,运行里面的启动脚本,首次会自动创建一个 Python 虚拟环境,并在里面安装依赖的各种工具包,比如 PyTorch 之类的,安装完以后就会自动启动。稍微详细一点的流程可以看我前面的记录:https://blog.iyatt.com/?p=12345
2024.1.28
2 环境
RAM:32G
CPU:i7-12700H
GPU:NVIDIA RTX4060 Laptop GPU
VRAM:8G
Windows 11 23H2
Stable Diffusion WebUI 1.7
3 资源网站
3.1 模型
3.2 插件
插件可以直接在 WebUI 里添加,可能有些没有收录到里面就要自己去下载,以及有些插件依赖模型需要手动下载,可以前往插件的项目页看README,会给出模型下载链接,基本上都是在开源代码托管平台 GitHub 上。
GitHub:https://github.com/
4 一些扩展(插件、脚本)
注:
- 添加扩展后一般都要点重启才能加载出来
4.1 汉化
- https://github.com/VinsonLaro/stable-diffusion-webui-chinese
- https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN
- https://github.com/hanamizuki-ai/stable-diffusion-webui-localization-zh_Hans
第一个插件支持中英同时显示,可以对照。第三个插件每过一段时间就会从云端同步,保持更新。
安装插件后进入设置,打开 User interface
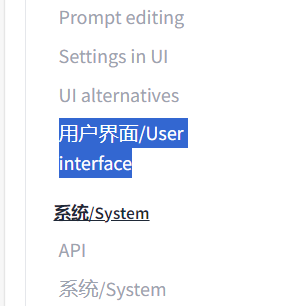
在 Localization 里选择语言
然后保存设置并重启 UI 生效
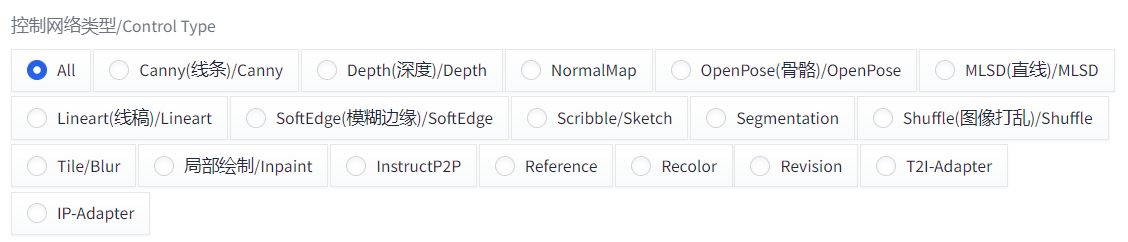
4.2 ControlNet
控制网络,通过各种网络控制生成内容,比如骨骼可以控制生成人物姿势。
4.3 中文提示词组及提示词翻译
- https://github.com/thisjam/sd-webui-oldsix-prompt
可以直接在里面选提示词,左键选进正面,右键选进负面

也可以按Alt+Q调出翻译框,自定义输入内容直接翻译
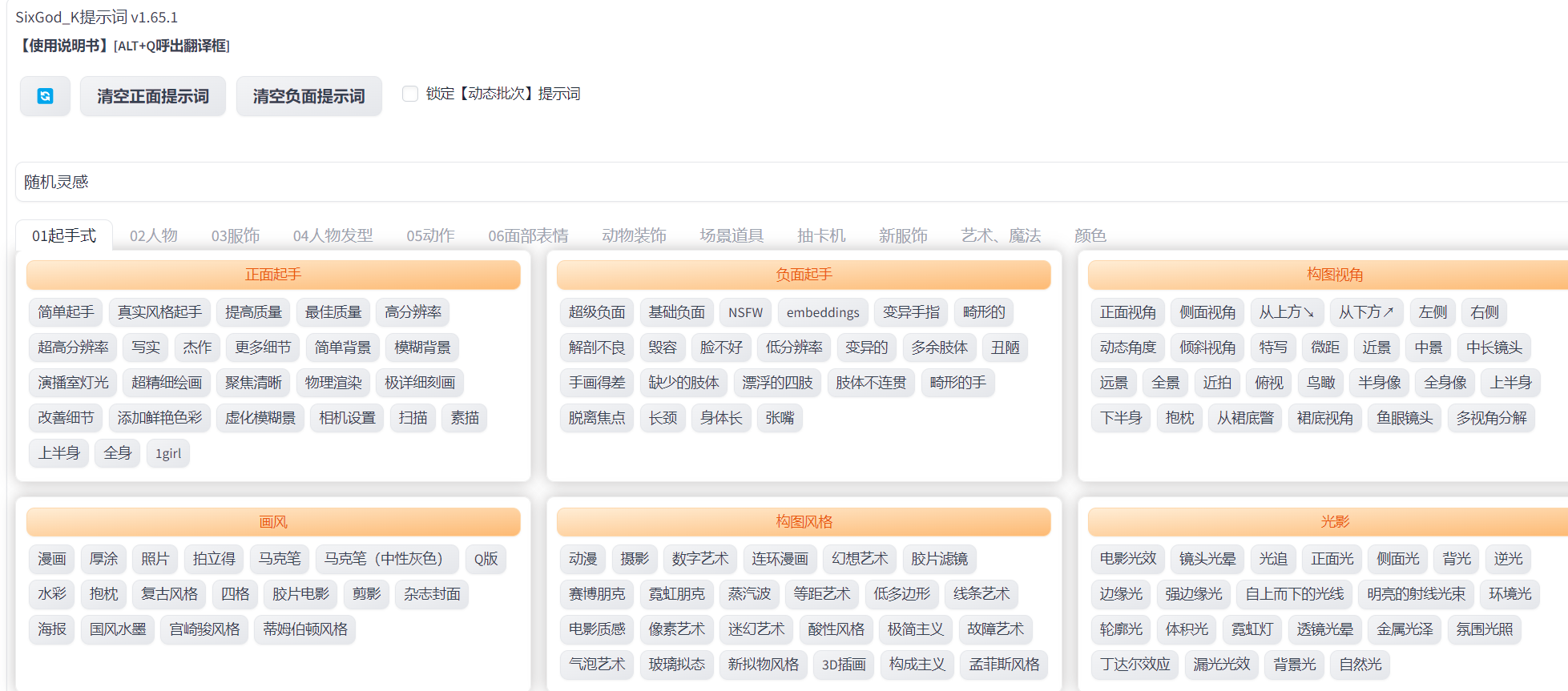
4.4 inpaint anything
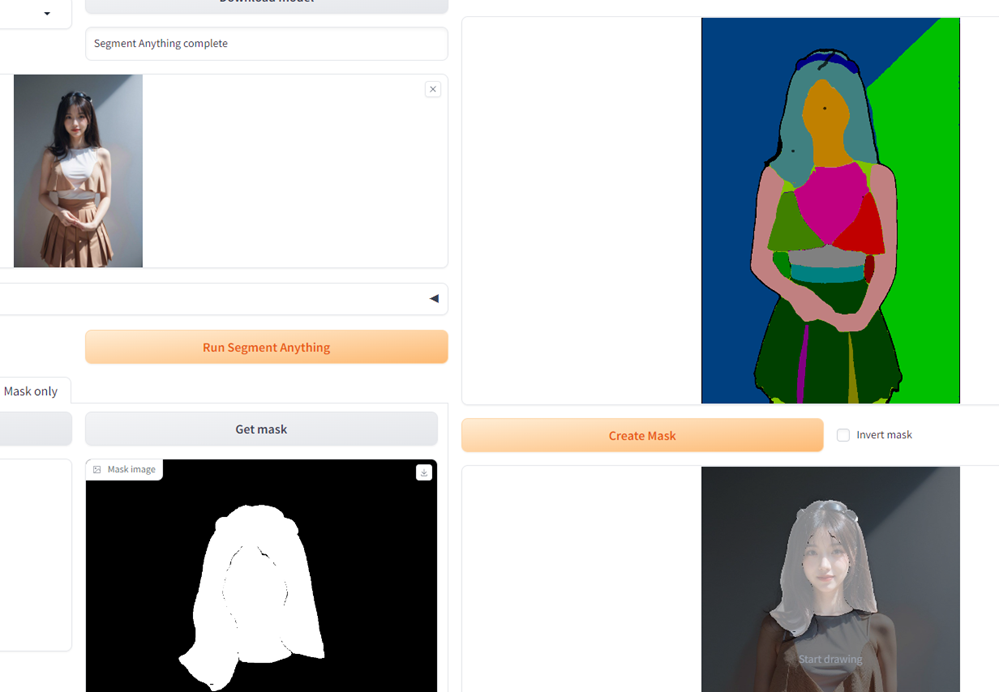
- https://github.com/Uminosachi/sd-webui-inpaint-anything
这个插件可以识别输入的图像,将图像中的各种元素分割开,主要是用来生成蒙版很方便。
4.5 Image browser
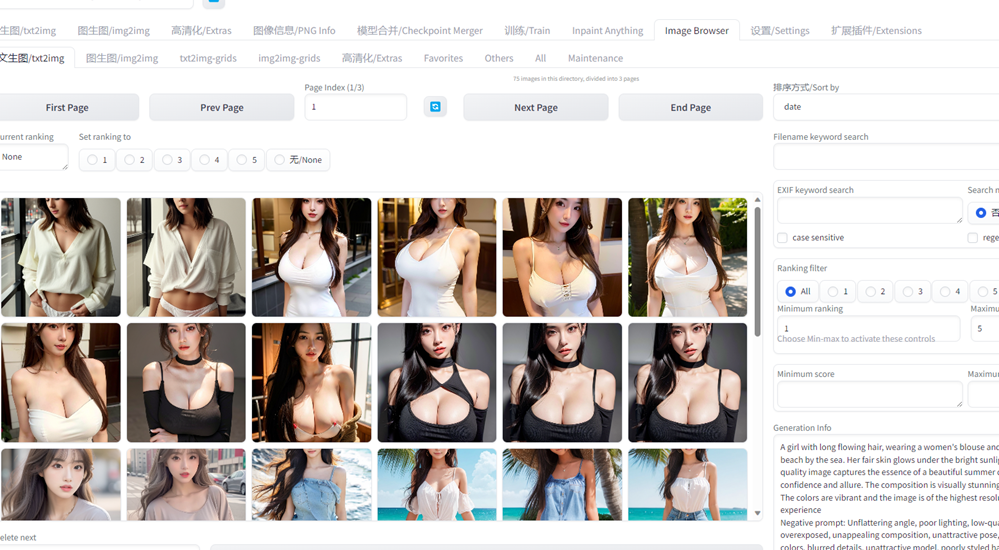
- https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
WebUI 生成的图片是按日期归档的,每天一个文件夹。Image browser 相当于相册,把所有图片全部显示在一起。
4.6 图生文反推提示词
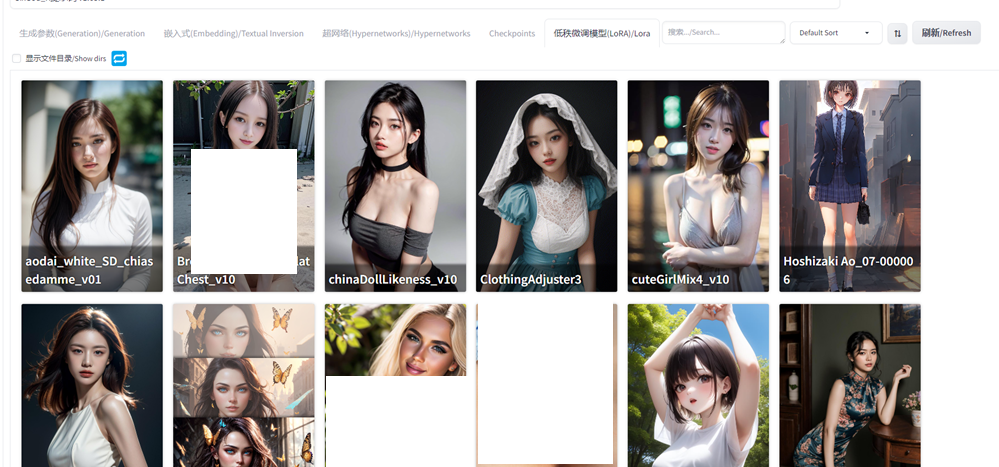
4.7 Civitai Helper
这个插件可以从 C 站同步模型的预览图,这样看到模型可以更好地联想到用途,另外支持通过模型的 C 站链接下载模型,而不需要手动下载再去移动文件到对应模型的路径。这个下载助手感觉用处不是很大,要么服务器在海外部署的,或者代理流量很足,直接用流量下也行,小模型用这个下载还行,大模型动辄几个 GB 起步,我一般就用迅雷下载,节省流量。
4.8 Adetailer
细节修复,比如脸、手画崩了可以用这个修复。
4.9 分块绘图
- https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
当直接绘制的图像尺寸超出显存可行范围,用这个插件可以实现大图拆小图,绘制多张小图,最后拼合成一张大图,这样对显存的需求就小了,只是绘图速度会更慢。
4.10 提示词补全
提示词输入时会显示候选,推荐更适合 AI 识别的关键词。
4.11 放大脚本
4.12 TensorRT 加速扩展
可以显著提高 Stable Diffusion 绘图速度
官网介绍:https://nvidia.custhelp.com/app/answers/detail/a_id/5487/~/tensorrt-extension-for-stable-diffusion-web-ui
项目主页地址:https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
最低配置要求:
- RTX 系列显卡且最低 8G 显存
- 最少 16G 内存
- 安装期间要保持网络连接(大陆区需要保持代理)
- 第四行的就是最低 NVIDIA 显卡驱动版本要求

可以自行查看驱动版本(在里面也能升级),如果是品牌电脑,预装的正版系统就是安装好驱动的,自己安装或者重装的记得自行打好驱动。官方驱动下载:https://www.nvidia.cn/geforce/drivers/

直接在 WebUI 列表里可以搜到,安装过程大约会下载几个 GB。
安装完重载 UI,可以看到
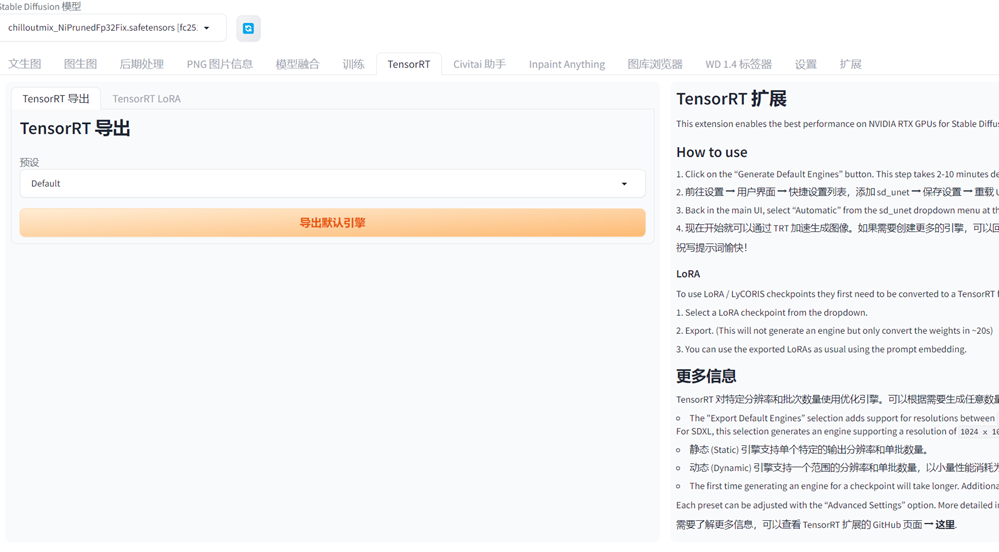
右侧有它的使用说明,如果遇到问题可以去看看项目页的 issues,没有人提过这个问题就自己提出来。
这个加速会丧失一定的自由度,比如生成图像的尺寸会固定某几个,或者一个范围,需要指定参数提前编译模型。这个东西感觉像 OpenVINO 版本的 WebUI,如果要使用 Intel 显卡加速,就要在绘图之前先重新编译模型,只是过程自动,但是有使用范围限制,生成图像尺寸限制,提示词数量限制等等。试参数绘制的时候,这个加速没啥用,有些参数改一下又要重新编译模型,反而更慢,比较适合大规模生成(抽卡选画得好的)。
这个加速的原理可以这样理解,比如要做一个铁锅,传统做法就是人工捶打,速度慢是不是?那我专门做一套生产线(模具),从铁材料到铁锅成型的流水线全自动,速度是不是就快了?但是只做一口定制形状、厚度、大小的锅单独去做一条生产线会花不少时间的,这时候还是传统手锤好,除非觉得这种参数的铁锅好,要量产,才会去做一条生产线,等生产线建好了再批量生产的时候速度就非常快了。上面说的只是 TensorRt 在 SD 中的角色作用,不是本质的“加速”实现,本质上在使用 TensorRT 前需要重新编译模型,这个模型就是专门针对显卡的计算优化过的,简化运算,削减精度,降低计算量。
4.13 视频生成
帧率是每秒的画面张数,总帧数和帧率的比值就是时长;闭环选 N 时生成的视频不会首位呼应循环,其它的会首尾相同,只是中间变化规律不同;帧插值选 FILM,后面选插值次数,会在 AI 生成的图片的基础上插入一些画面进行衔接,减少 AI 生成的图片数,在一定程度上可以缩短生成时间;可以上传视频来“指导”视频动作生成。
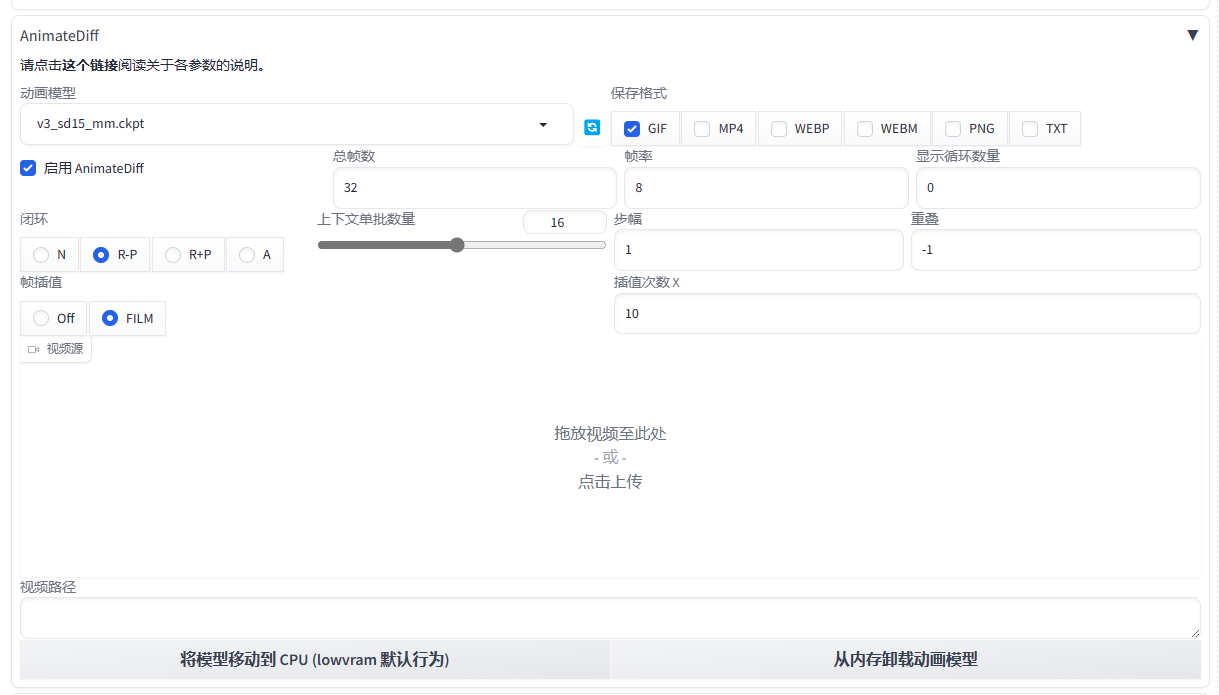
插件的设置中

建议项
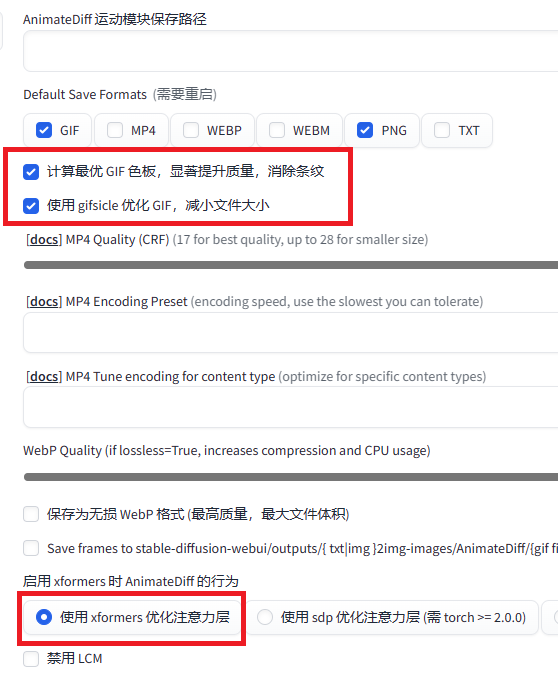
优化设置中的建议项(一定程度上可以缓解画风突变)
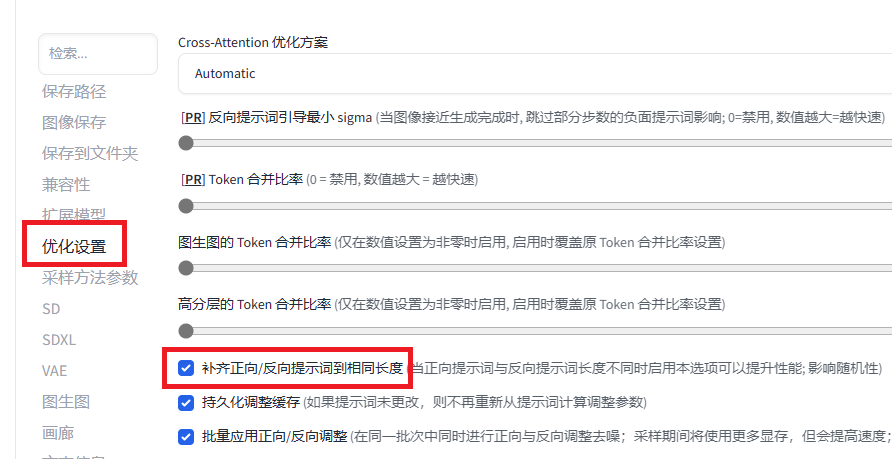
5 一些问题
5.1 no module ‘xformers’ 及 ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问
启动时可以看到
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.xformers 是一个加速框架,输出信息说没有,那么就安装。
进入 WebUI 根目录,可以看到有个 venv 目录,这是 WebUI 使用的 Python 虚拟环境,安装的 Python 包就在里面,首先确认当前用户是否具有修改和写入权限。否则后面安装模块时报错ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问。
在 venv 文件夹上右键点开属性,在安全选项卡中选中当前用户名。我这里就没有修改权限,点编辑,勾选修改权限,会自动同时勾选写入权限,再确定就会开始更改文件权限。
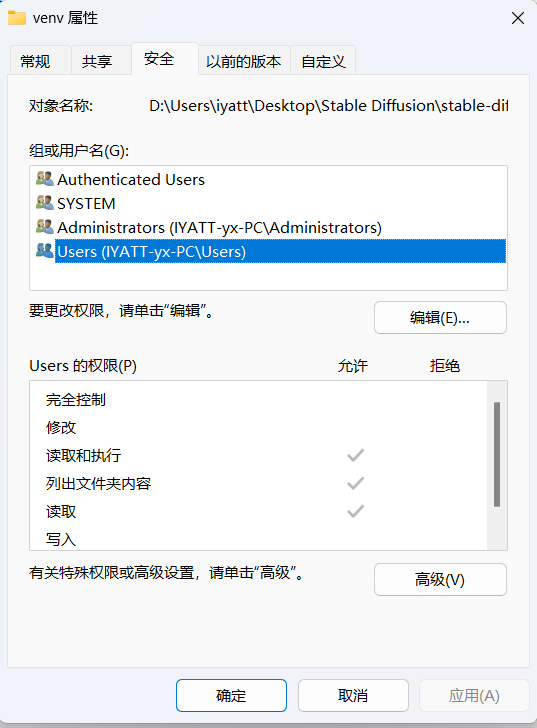
权限修改完后进入 venv 目录,右键打开 PowerShell
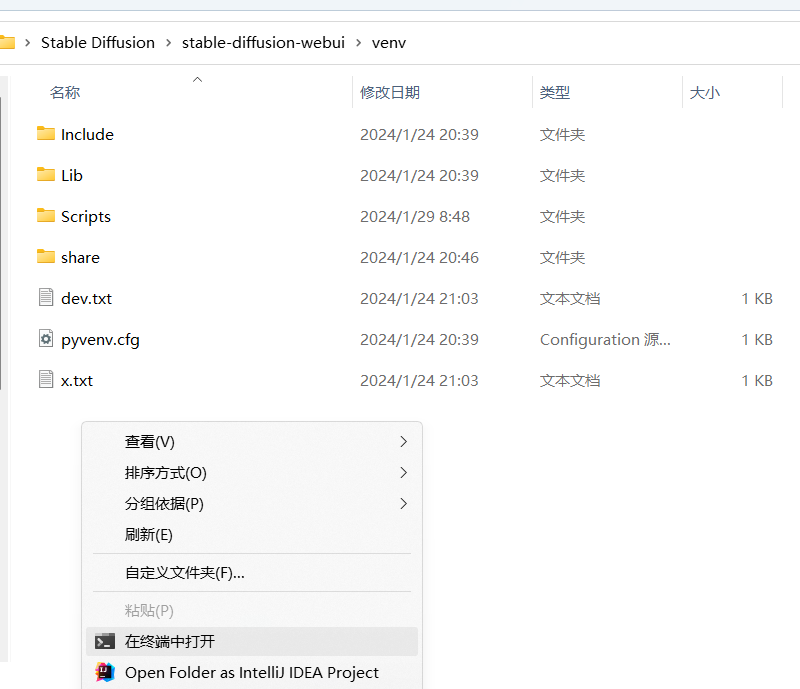
执行命令进入虚拟环境
.\Scripts\activate因为 xformers 是在 PyTorch 基础上构建的,所以与 PyTorch 有关联,最开始我尝试直接安装 xformers (默认最新版),结果把 PyTorch 版本一起更新了,WebUI 中依赖 PyTorch 的可不止这一个,PyTorch 一更新,依赖关系就乱了,导致其它组件出现问题。我去查了 xformers 项目的 README,并没有找到关于依赖版本关系的说明,这就有点难搞了。
后面参考了这篇文章的思路:https://www.felixsanz.dev/articles/compatibility-between-pytorch-cuda-and-xformers-versions
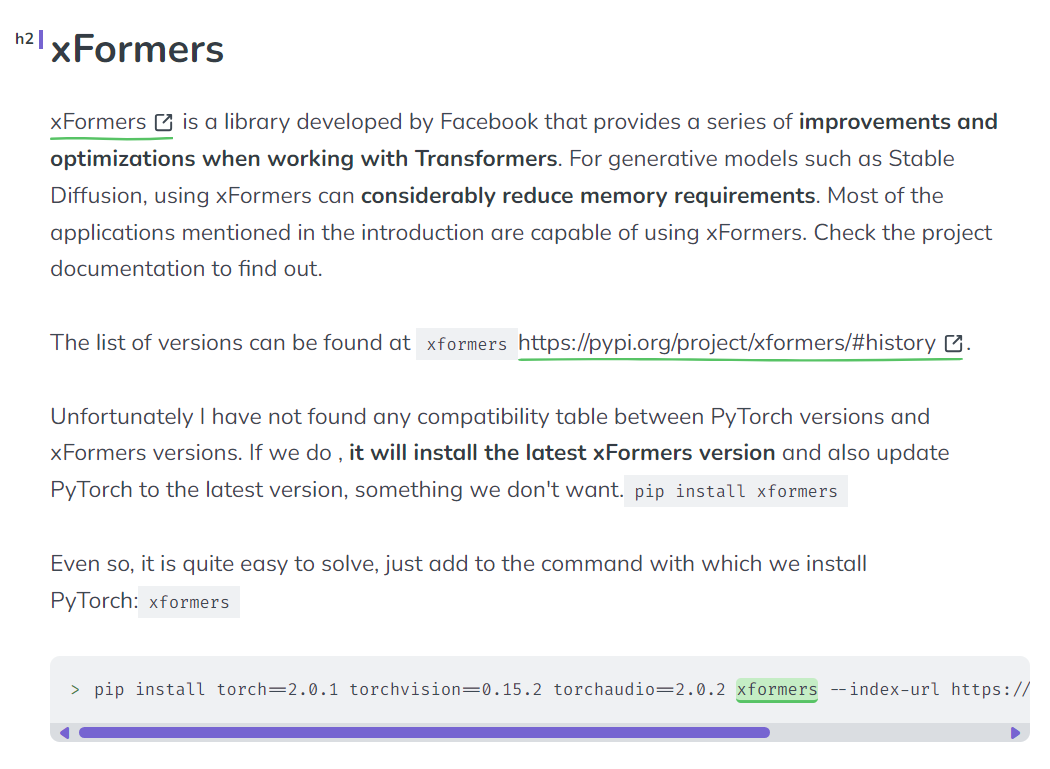
在安装的时候把 PyTorch 的版本固定住,那么 xformers 版本不就能自动匹配了吗?
所以先查询本地已经安装的 PyTorch 版本
pip list | findstr torch
注意其中的 torch 和 torchvision 版本
根据我这里查到的版本,就可以采用如下命令安装(这里要结合自己环境的实际版本),
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 xformers然后编辑启动脚本 webui-user.bat,参数里加上 –xformers
再次启动 WebUI 就不会看到说没有 xformers 了
6 折腾记录
6.1 图像放大
这里使用一张文生图绘制的 512×768 图片示例

6.1.1 后期处理
把文生图的提示词和图片发到后期处理
设置一下放大算法和缩放比例
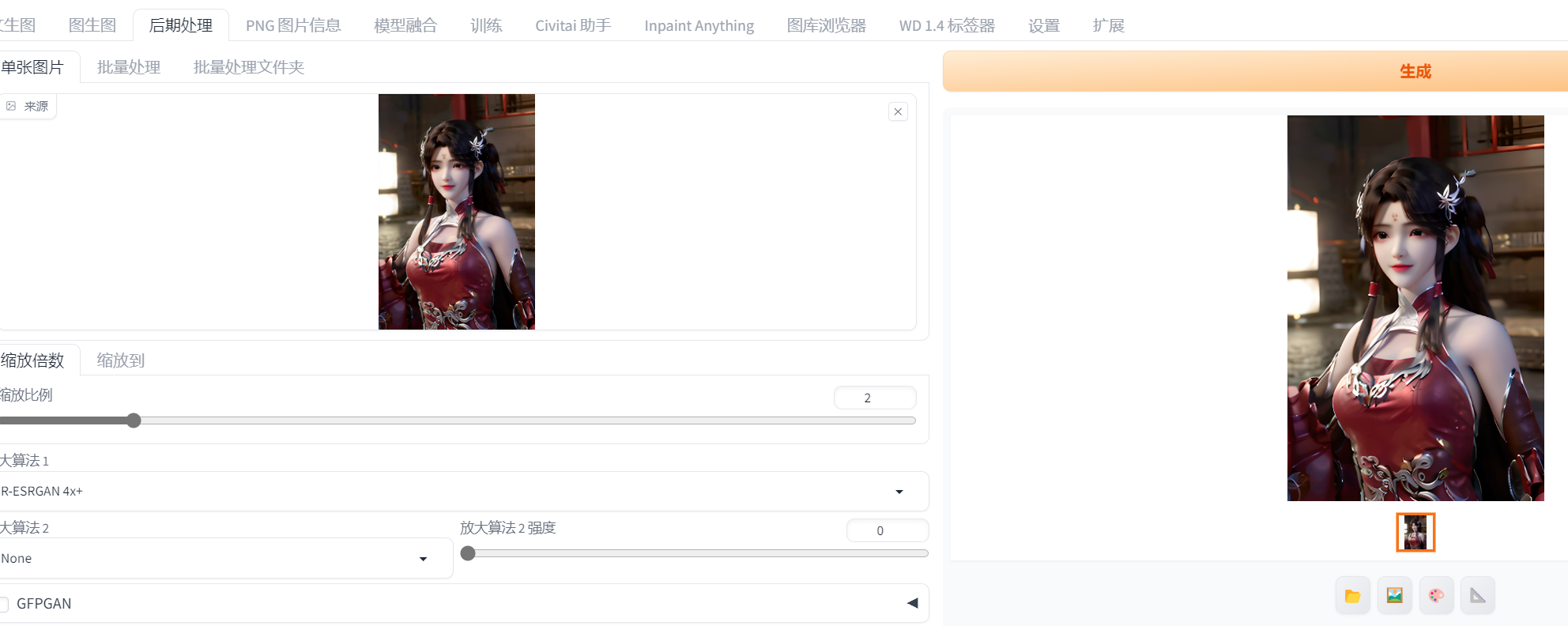
这种放大方法相当于零重绘,把图像分辨率拉大,通过一定的算法去填充拉大产生的空隙的像素,效果不咋样,但是不涉及 AI 重绘速度快(即使没有独显也能跑起来)
比如一张64×64的图上有一个人,因为像素点不足,无法清晰呈现这个人,就是一坨马赛克,你用这个后期处理放大后它依然是一坨马赛克,因为原图也没有足够呈现细节的东西,放大填充的像素是根据临近像素颜色按照一定算法得到的。而后面的放大方法都是涉及 AI 重绘的,则不存在这个问题,如果缺少信息,AI 会进行创作补充,至少看起来更好看。
6.1.2 图生图
打开设置,系统设置-放大
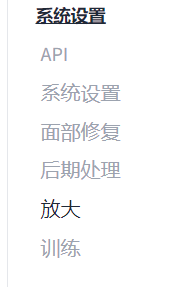
设置一下图生图的放大算法,记得保存设置
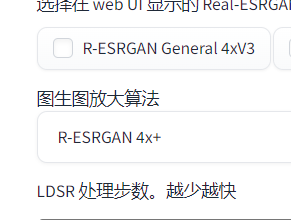
将文生图的提示词和图片发送到图生图,主要就是设置放大后的分辨率(或放大倍数)以及重绘幅度,建议以 0.3 为基准,后续一样,越低改动越少,就越接近于上面后期处理的效果,纯纯的放大,越大 AI 发挥就越多,对原图的改动就越多,0.3 的基准差不多适中,增加缺失的细节,又不会太明显改动图片。
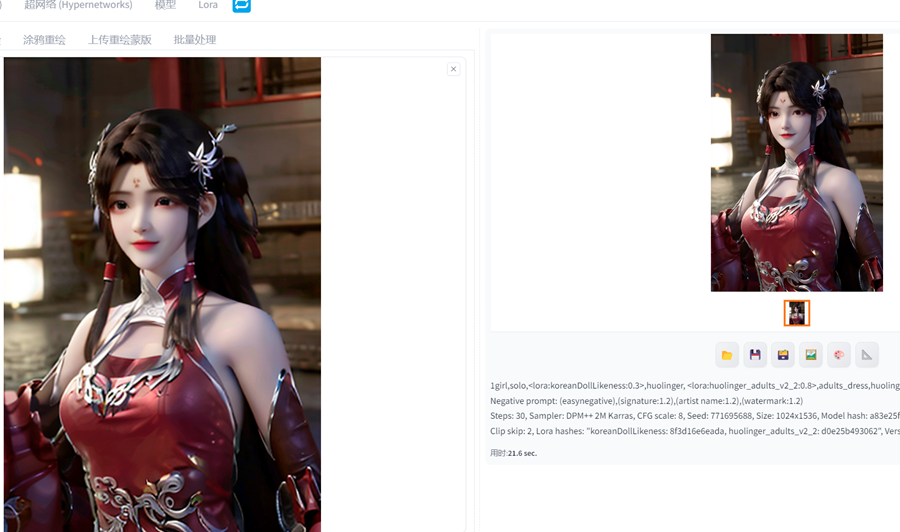
效果呈现明显比原图清晰多了
6.1.3 SD 放大脚本
还是使用图生图,只是增加脚本选择 SD Upscale。这种放大方法会把图像分块,按块画好再拼接,减小对显存的压力,参数中的分块重叠宽度是预留用来相邻块拼接的,避免拼接的图像产生明显的边界
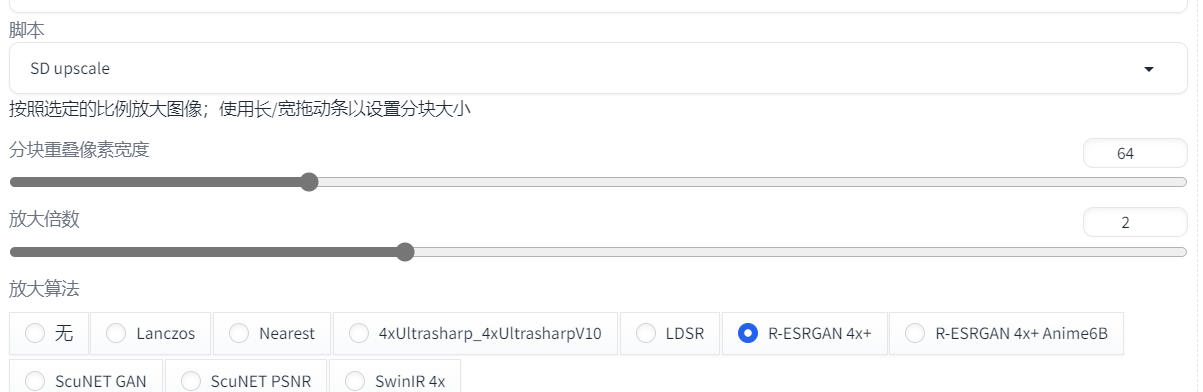
下面的图就是把分块重叠宽度设置为 0,可以看到有一条明显的边界线

图生图放大应该也有采用分块的策略,我在测试放大两倍的时候显存是满载的,放大三倍也是满载的,如果是一次性画的,两倍都满载了,三倍必然会爆显存,然后生成失败,而且放大过程终端可以看到 Tile,只是参数不可控,SD 放大脚本还可以设置重叠区域大小。
6.1.4 Ultimate SD 放大脚本
这个就是上面扩展部分提过的,属于自己添加的第三方脚本。
一样使用图生图,可控制的参数更多了,包括分块大小等等,注意宽度和高度如果只设置了其中一个那么就会是一个正方形的分块
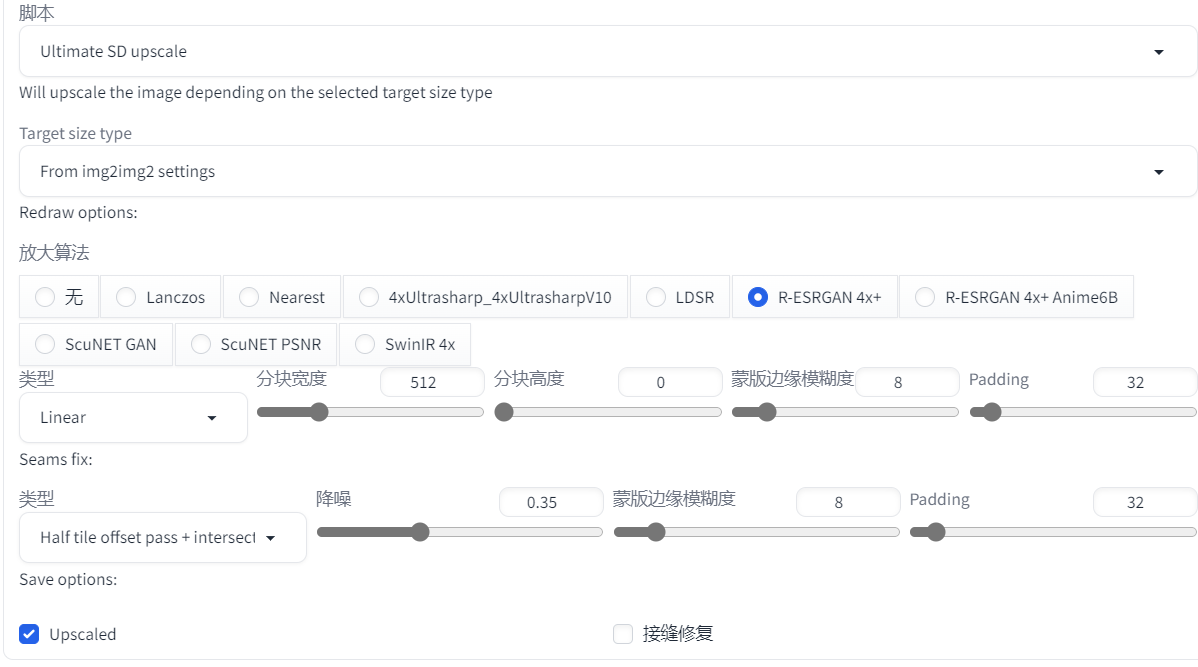
6.1.5 分块绘图插件
这个也是上面扩展部分提到的第三方插件。
图生图本身可以用于图像放大,但是分块绘制的参数不可控,使用这个插件就可以,而且不仅限于用于放大,在图生图的其它应用中也可以使用,以及在文生图中也可以使用,显存小想要画大图的,这个插件就是利器,当然因为图像拆分为很多小块来画,为了衔接每张小图交界处,则要重复绘画,就是额外的时间开销,以及不能一次性在显存中呈现数据,在显存和内存之间搬运数据也是时间开销,这个插件可以说是用时间换空间的不足。
这个插件的配置项有两个,上面的是在 Diffusion(扩散)过程起作用,也就是 AI 重绘过程,下面的是在编码过程起作用。

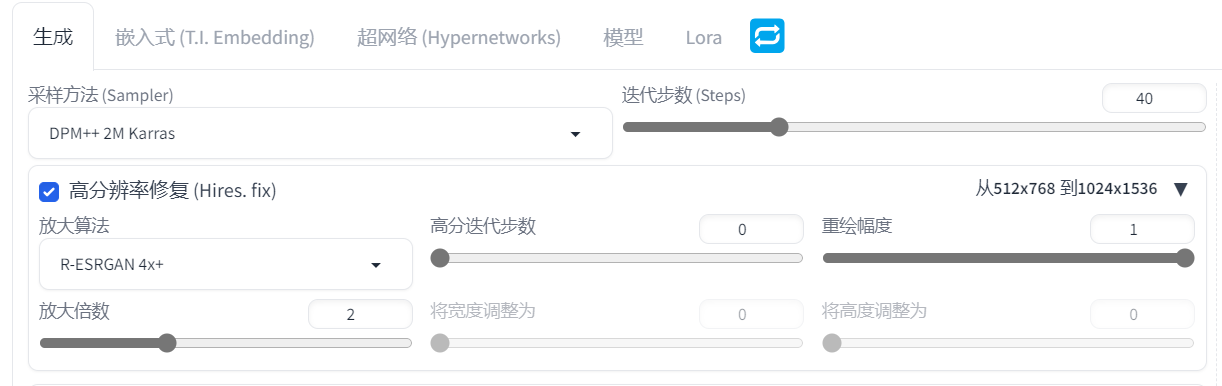
6.1.6 高分辨率修复
高分本身就是一种图生图,只是集成到文生图中一起工作。
6.1.7 ControlNet 辅助
这张图是文生图+高分放大+分块绘图画的

然后我把没有使用高分放大生成的图发到 ControlNet,模型选分块
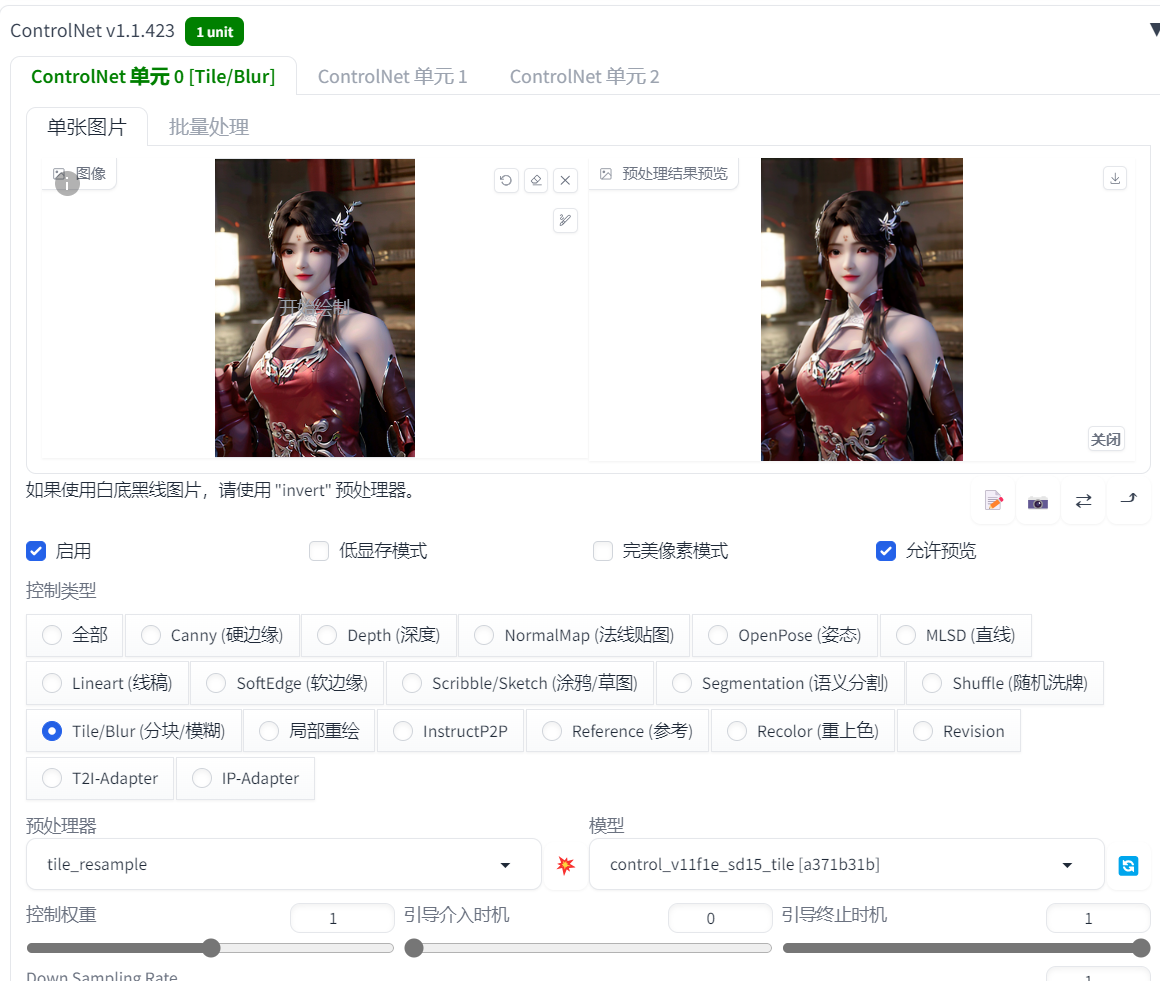
即文生图+高分放大+分块绘图+ControlNet,再次绘制

整体画质感觉更好了,特别是有时候使用分块绘图参数没调好,容易画出多个身体多个头之类的情况,加上 ControlNet 的 Tile 模型,这种情况就能有效减小,Tile 模型会对每个分块内容进行识别,通过输入 ControlNet 的图片分块控制每个分块绘图时侧重点,避免绘制不相干的内容。
同样这个插件也不限于文生图使用,图生图也可以使用。
6.2 艺术图案
主要是基于 ControlNet 的应用
6.2.1 艺术字
使用文生图,在提示词描述文字的效果

这里我用画图打的字,然后截图放到 controlNet 中,模型选深度
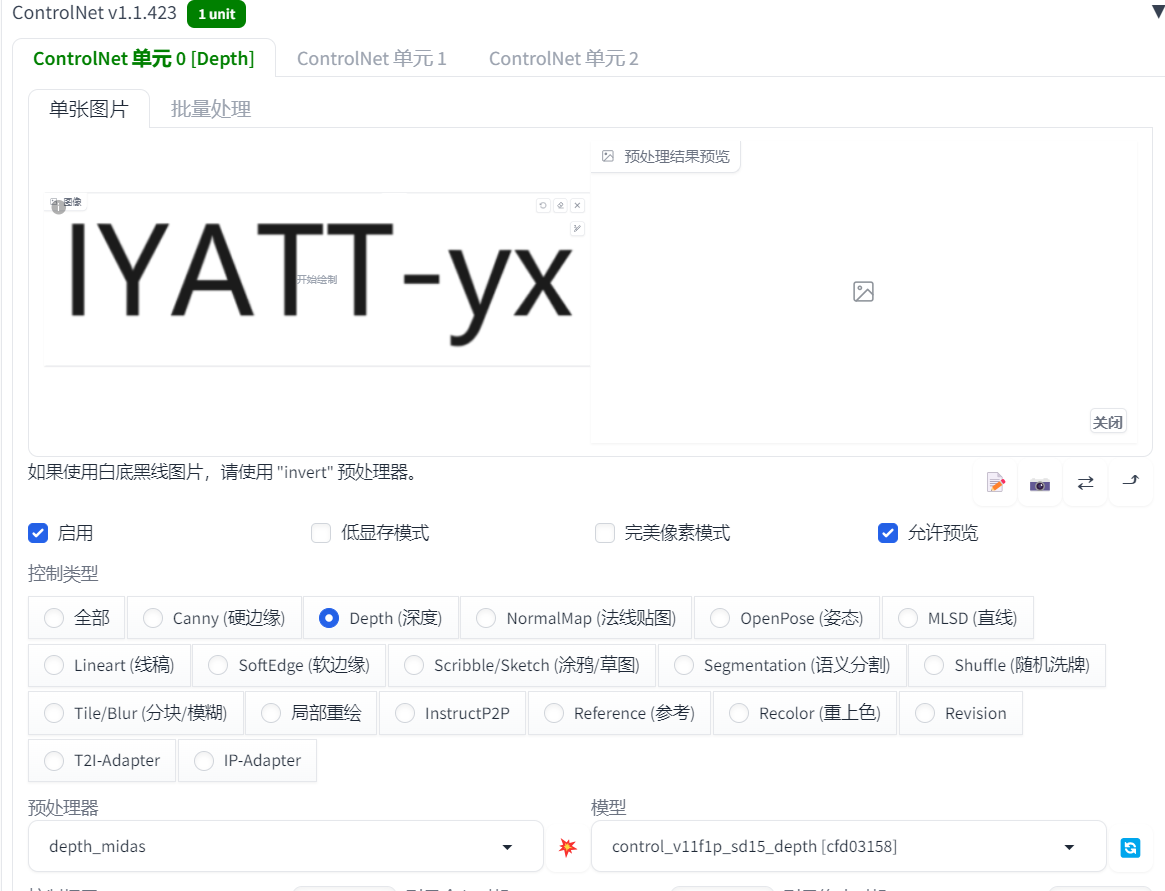
然后绘制的图片

这张是 ControlNet 模型选的硬边缘绘制的

线稿

线稿+invert预处理器(非默认预处理器)画得就有点抽象了

6.2.2 光影文字
这里需要下载两个第三方 ControlNet 模型:https://huggingface.co/ioclab/ioc-controlnet/tree/main/models
放到 ControlNet 插件的模型目录里
文生图,这里还是使用前面画火灵儿的提示词
ControlNet 控制类型选全部,上传一张文字图片,预处理器用 invert,模型用前面下载的 brightness
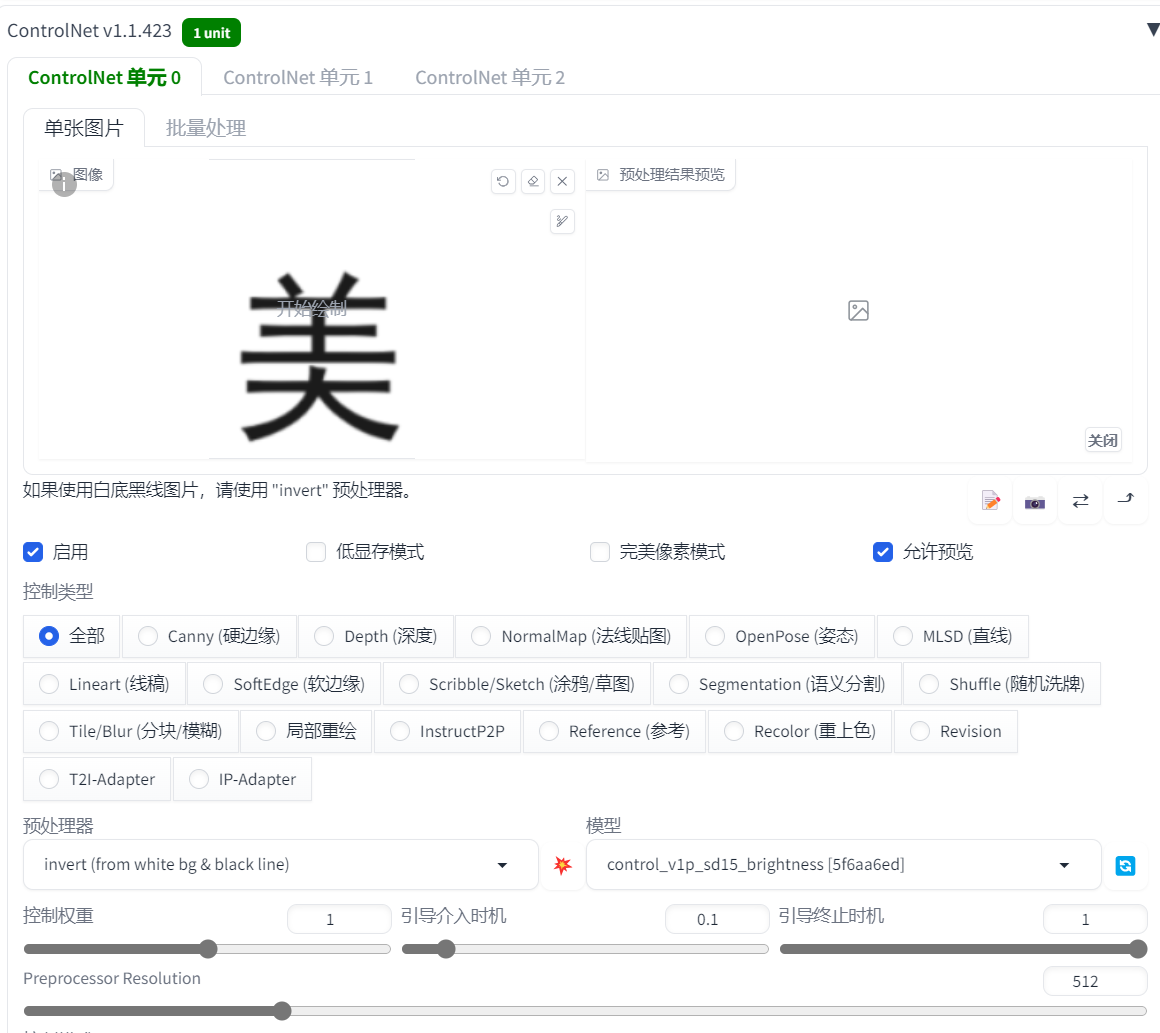
控制要以提示词为主,不然白底黑字的 invert 处理后是黑底白字,然后画图一片黑
大致实现远看是字,近看是亮度以及身体物体变化的效果

预处理器不使用反转,选无

具体使用的时候要不断尝试调参,预处理器也可以尝试别的。
brightness 在控制权重较高时,可能会通过物体形状颜色变化来表现图案,控制权重低时偏向光照亮度变化。而下载的另外一个模型 illuminate 则本身偏向于光影展现图案,感觉画出来也更亮一些。

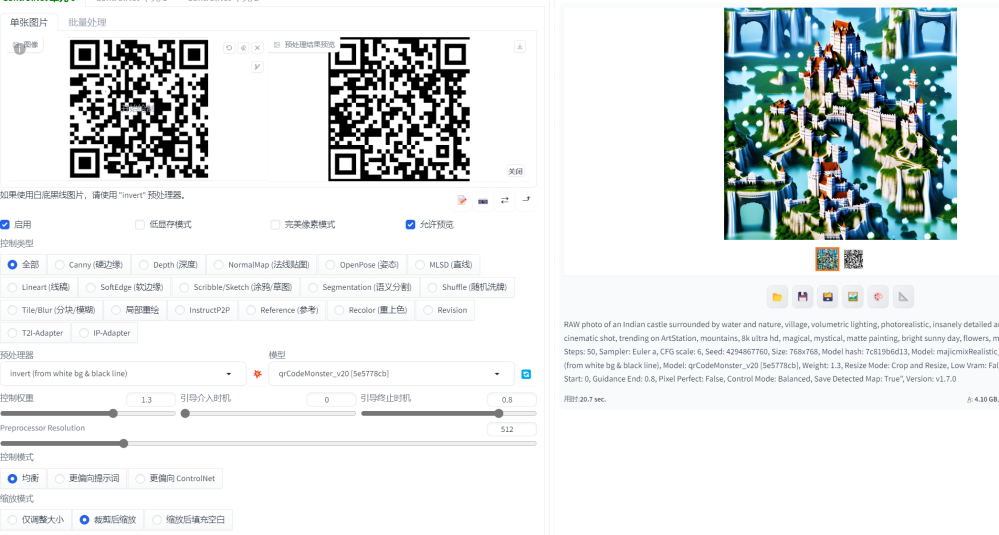
6.2.3 嵌入二维码
这里可以使用上面的 brightness,也可以使用专门训练用于二维码嵌入的 ControlNet 模型:https://civitai.com/models/111006/qr-code-monster
至于要美观效果还是要能识别出来,就需要调参测试了,不同的绘图颜色形状不一样,参数控制也不一样
6.3 以图片作为“提示词”,画风修改 – 适配器
使用 ControlNet,需要用一个适配器模型叫 IP-Adapter,这个模型是腾讯搞的,下载地址:https://huggingface.co/h94/IP-Adapter/tree/main/models
演示就用的图生图,把前面画的火灵儿重绘。ControlNet 中添加了一张风景图,用来作“提示词”
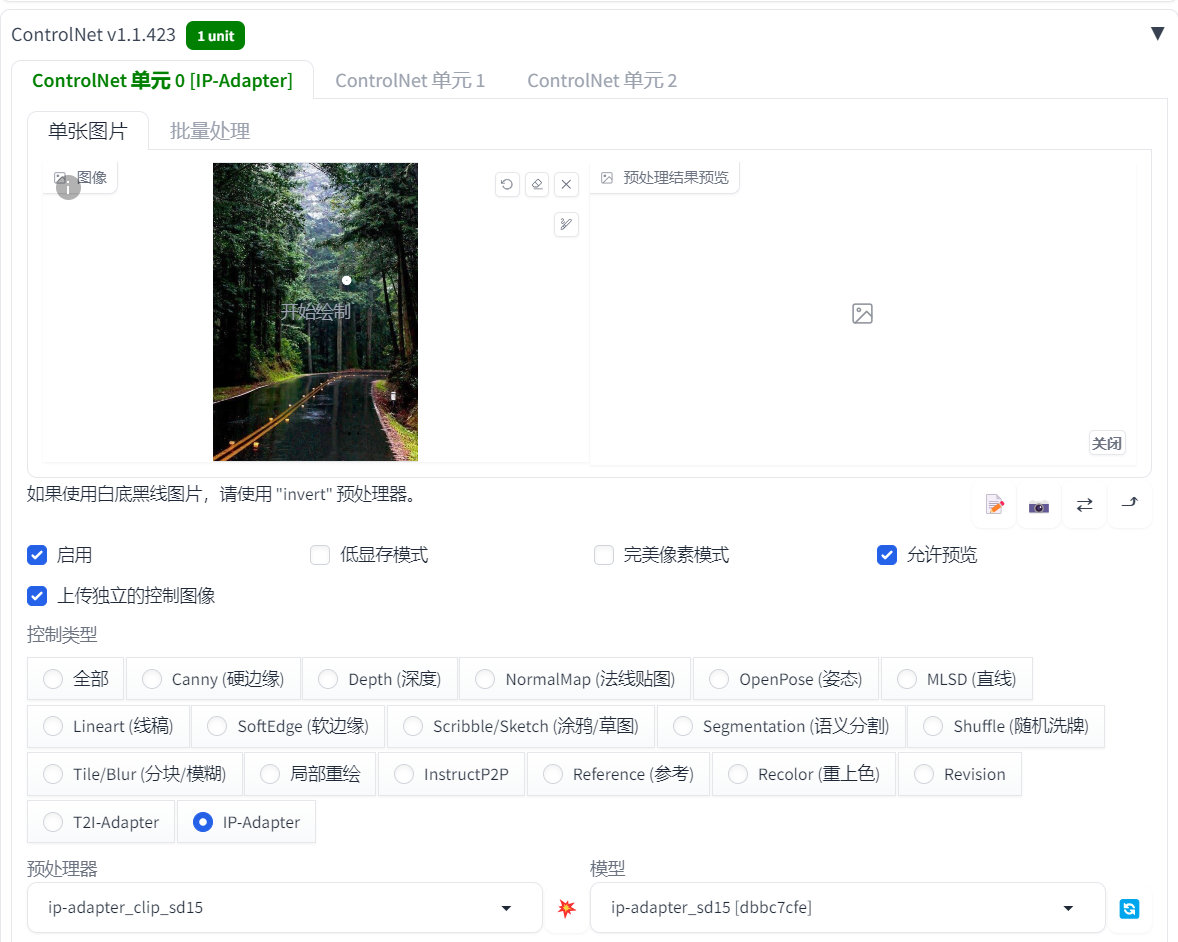
根据输入的图片来重绘图片风格

6.4 局部重绘 – 换衣、“去衣”
局部重绘需要蒙版(涂抹要重绘的区域),可以手动涂绘

也可以使用前面提到的 inpaint anything 插件识别元素制作蒙版
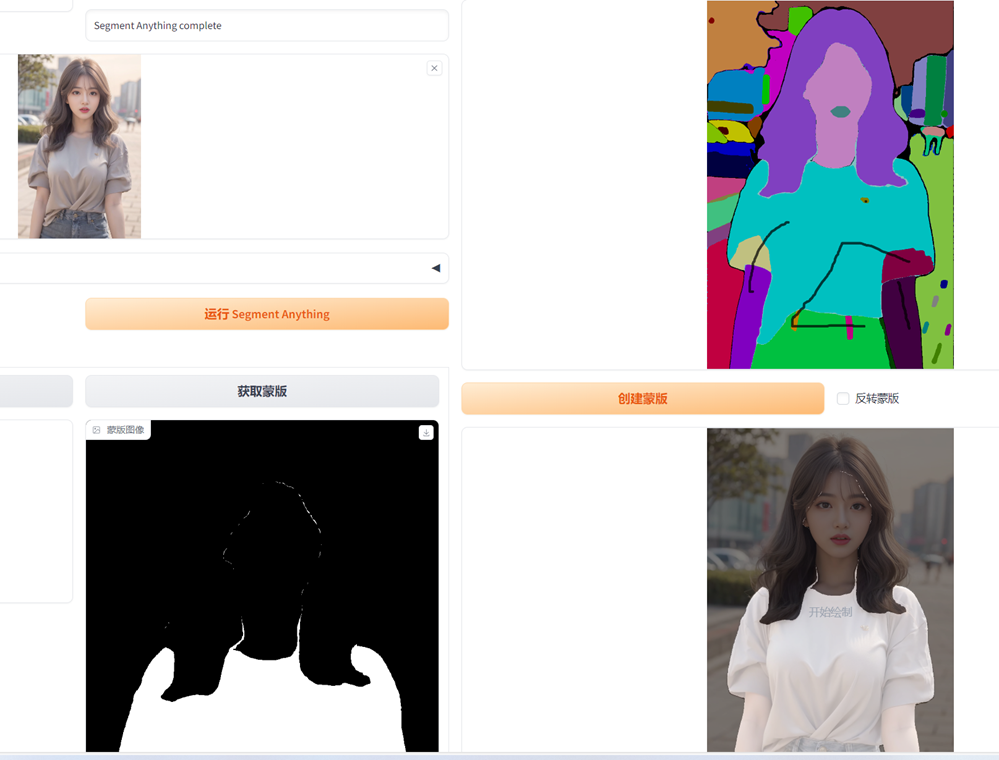
我这里就用 inpaint anything 制作的蒙版
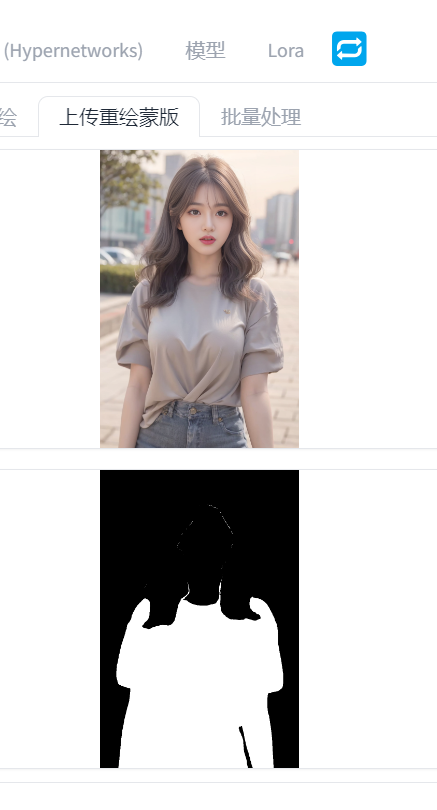
我这里是去衣,要换衣可以描述服装
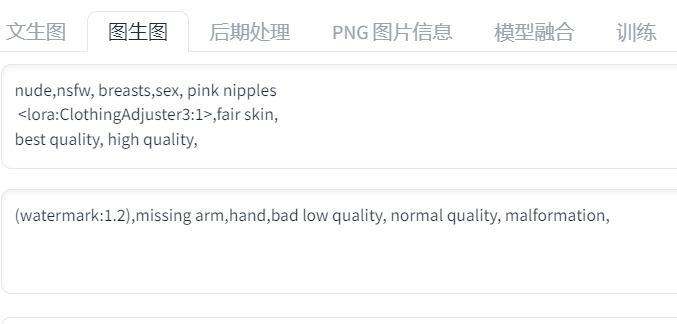
可以只重画蒙版的部分
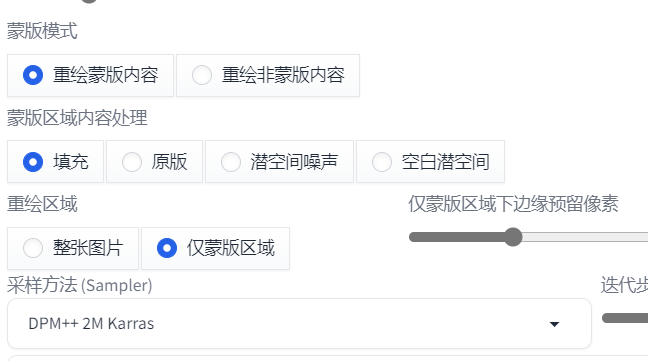
配合 ControlNet 的 inpaint 模型,可以获得更好地质量。换衣要控制风格的话,可以结合前面提到的 IP-Adapter 模型等等,多个 ControlNet 模型可以同时使用的。