最近更新于 2024-05-05 14:18
环境
①
Debian 11 (arm64)
编译:
- C 语言:编译器 gcc 10.2.1;编译标准 C17;参数:-std=c17 -no-pie -Wall -Werror=return-type -Werror=address -Werror=sequence-point -Werror=format-security -Wextra -pedantic -Wimplicit-fallthrough -Wsequence-point -Wswitch-unreachable -Wswitch-enum -Wstringop-truncation -Wbool-compare -Wtautological-compare -Wfloat-equal -Wshadow=global -Wpointer-arith -Wpointer-compare -Wcast-align -Wcast-qual -Wwrite-strings -Wdangling-else -Wlogical-op -Wconversion -g -O0
- C++:编译器 g++ 10.2.1;编译标准 C++20;参数:-std=c++20 -no-pie -Wall -Werror=return-type -Werror=non-virtual-dtor -Werror=address -Werror=sequence-point -Werror=format-security -Wextra -pedantic -Wimplicit-fallthrough -Wsequence-point -Wswitch-unreachable -Wswitch-enum -Wstringop-truncation -Wbool-compare -Wtautological-compare -Wfloat-equal -Wshadow=global -Wpointer-arith -Wpointer-compare -Wcast-align -Wcast-qual -Wwrite-strings -Wdangling-else -Wlogical-op -Wconversion -g -O0
②
Windows 11 专业工作站版 22H2
平台工具集:Visual Studio 2022 v143
编译标准 C17/C++20
警告等级:启用所有警告
注:下面例子中,符合 C/C++ 标准的采用 ① 编译运行,标准未规定的行为(称为 UB,下同),将同时使用 ① 和 ② 编译运行
C 语言
#include <stdio.h>
int main()
{
int a = 10;
int b = ++a;
printf("a=%d,b=%d\n", a, b);
int c = a++;
printf("a=%d,c=%d\n", a, c);
int d = --a;
printf("a=%d,d=%d\n", a, d);
int e = a--;
printf("a=%d,e=%d\n", a, e);
return 0;
}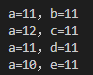
上面对自增自减的使用是符合规范的使用,操作符在前,赋给变量的值就是自增或自减后的,操作符在后就是赋自增或自减前的值
而下面的情况就是 UB 行为,至少在我这里测试的 C17 和 C++20 中都没有规定
#include <stdio.h>
int main()
{
int a = 10;
int b = (++a) + (++a);
printf("a=%d,b=%d\n", a, b);
a = 10;
int c = (a++) + (a++);
printf("a=%d,c=%d\n", a, c);
a = 10;
int d = (++a) + (a++);
printf("a=%d,d=%d\n", a, d);
a = 10;
int e = (--a) + (--a);
printf("a=%d,e=%d\n", a, e);
a = 10;
int f = (a--) + (a--);
printf("a=%d,f=%d\n", a, f);
a = 10;
int g = (--a) + (a--);
printf("a=%d,g=%d\n", a, g);
a = 10;
printf("a=%d,++a=%d,a++=%d\n", a, ++a, a++);
a = 10;
printf("a=%d,++a=%d,++a=%d\n", a, ++a, ++a);
a = 10;
printf("a=%d,a++=%d,a++=%d\n", a, a++, a++);
a = 10;
printf("a=%d,--a=%d,a----=%d\n", a, --a, a--);
a = 10;
printf("a=%d,--a=%d,--a--=%d\n", a, --a, --a);
a = 10;
printf("a=%d,a--=%d,a--=%d\n", a, a--, a--);
}环境 ① 编译
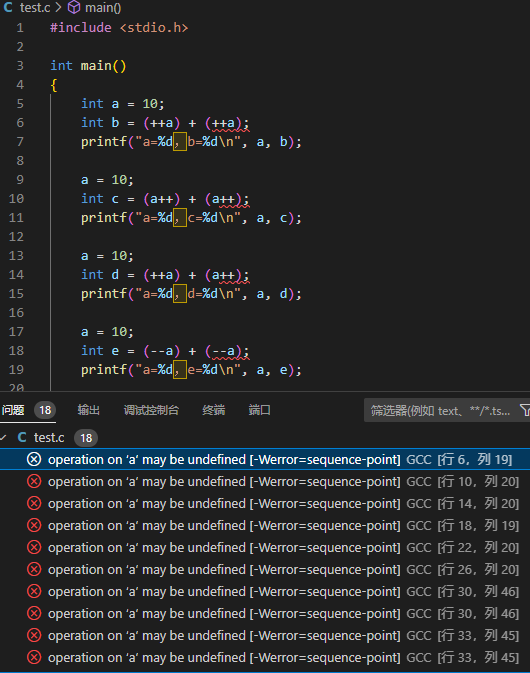
在 -Werror=sequence-point 参数下就检测到了 UB
在同一个语句中,对同一个变量,多次自增/自减操作,它的值是不确定的。比如 (++a) + (++a),第一个 ++a 的值确实是原来的 a 的值再加一,那么后面那个表达式再次执行 ++a 时,究竟是在原来的 a 上加一,还是在加一后的值上加一,C 语言标准中并没有规定。后面在 printf 中的操作,也是这个道理。
在开发中就要避免这样使用,标准没有规定行为,它的结果就是看编译器怎么做,这样写出来的程序就具有不确定性。你自己写的时候编译运行符合自己的要求,但是把源码给别人编译运行时,用的编译器不同结果就可能会改变。下面就做个对比
现在还是按照环境 ① 编译,但是忽略这种错误检查
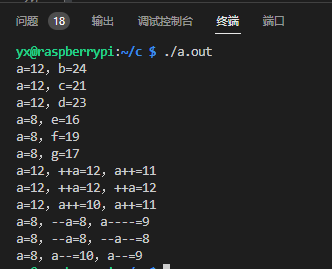
环境 ② 编译时,即使设置启用了所有警告都没指出这个
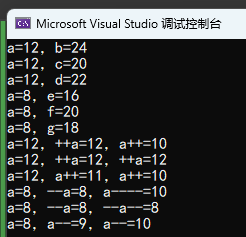
同样的代码,部分出现了结果不同的情况,即使相同的部分,再换一种编译器说不定可能又会不同,就看编译器怎么做
C++
上面的代码在 C++ 支持的范围内,所以继续使用上面的代码再分别按照 C++ 来编译
环境 ①
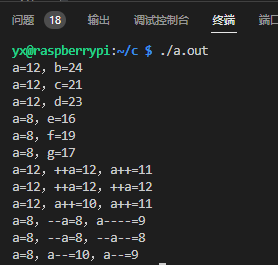
环境 ②
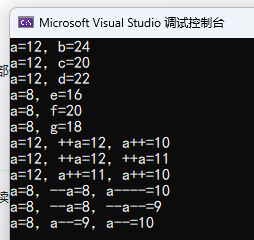
环境 ① 的结果和 C 语言一样,环境 ② 的就有差别了,同一个编译器,按照 C 和 C++ 分别编译运行的结果出现了不同。当然也不能要求它们一样,毕竟 C 和 C++ 是两门不同的语言,各自有各自的标准,再说这个是 UB,怎么做是编译器的自由,只是说微软的 MSVC 在 C 和 C++ 的这种 UB 处理上使用了不同的逻辑。