最近更新于 2024-05-05 14:19
题目
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/two-sum
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
Python3
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
size = len(nums) # 输入数组的大小
for i in range(size-1): # 第一个加数从数组第一个开始,倒数第二个结束
add_num = target - nums[i]
if add_num in nums[i+1:]: # 第二个加数从第一个加数的后一位开始,最后一个结束
return [i, (nums[i+1:].index(add_num) + i + 1)]
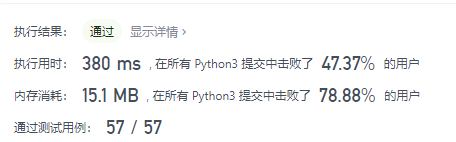
这个是暴力枚举,依次两个两个地挑选看是否满足条件。

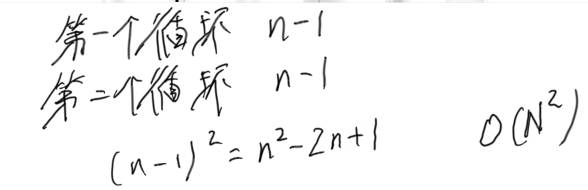
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
size = len(nums)
dict = {}
for idx, val in enumerate(nums):
dict[val] = idx # 将数组每一个元素放入字典,元素值对应下标
for idx, val in enumerate(nums):
add_index = dict.get(target - val) # 求出另外一个加数,并搜索字典中是否存在,存在且不是重复第一个就找出来了
if add_index is not None and idx != add_index:
return [idx,add_index]
相比于前面暴力的解法,时间降了一个数量级,我提交几次,时间波动一点,显示的击败用户百分比却有十几二十的跳动,这点时间变化是随机不可控的,在能忽略的范围内。
Python 中字典的搜索是基于哈希查找,时间复杂度为 O(1)。
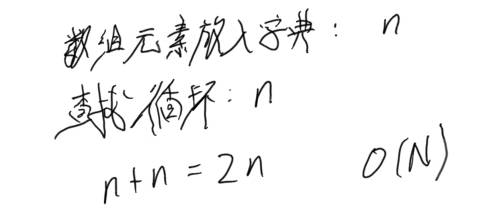
C
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
int *result = (int *) malloc(sizeof(int *) * 2); // 申请两个整数大小的内存空间
memset(result, 0, sizeof(result)); // 初始化为 0
for (int i = 0; i < numsSize - 1; ++i)
{
for (int j = i + 1; j < numsSize; ++j)
{
if (nums[i] + nums[j] == target)
{
result[0] = i;
result[1] = j;
}
}
}
*returnSize = 2; // 说实话没理解这个参数的意义,明明题目说了返回两个结果的下标,还要我来告诉?
return result;
}
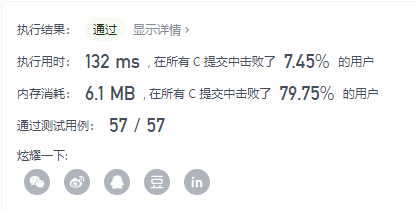
这个也是暴力枚举法,不过和 Python 比起来,速度还是快一倍左右。当然这是在传入数组只有几个元素的情况下,如果成百上千处理的时候,差距应该就会明显起来。
/**
@struct 类似于 Python 中字典的结构(键-值)
*/
typedef struct hashTable
{
int key;
int val;
UT_hash_handle hh; // uthash:https://github.com/troydhanson/uthash
} hashTable;
hashTable *hashtable = NULL;
/**
@brief 查找哈希表
@param key 查找值
@return 找到的哈希节点,未找到返回 NULL
*/
hashTable *find(int key)
{
hashTable *tmp;
HASH_FIND_INT(hashtable, &key, tmp);
return tmp;
}
/**
@brief 哈希表插值
@param ikey 插入键
@param ival 插入值
*/
void insert(int ikey, int ival)
{
hashTable *it = find(ikey);
if (it == NULL) // 不存在则插值
{
hashTable *tmp = (hashTable *) malloc(sizeof(hashTable));
tmp->key = ikey;
tmp->val = ival;
HASH_ADD_INT(hashtable, key, tmp);
}
else // 存在则修改
{
it->val = ival;
}
}
int *twoSum(int *nums, int numsSize, int target, int *returnSize)
{
hashtable = NULL;
for (int i = 0; i < numsSize; ++i)
{
hashTable *it = find(target - nums[i]);
if (it != NULL)
{
int *ret = (int *) malloc(sizeof(int) * 2);
ret[0] = it->val;
ret[1] = i;
*returnSize = 2;
return ret;
}
insert(nums[i], i);
}
*returnSize = 0;
return NULL;
}
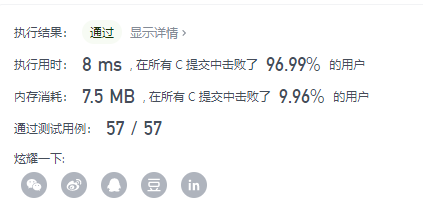
该算法的查找部分是基于哈希查找,代码中实现了一个类似于 Python 字典的结构。思路主体和 Python 的一样,但是有点小不同。Python 代码我写的是先将所有数组元素插入字典,后面循环的查找的时候,每次查找都要将所有数组元素搜索一遍。而这里我用 C 写的时候换了个方式,哈希表先为空,每次循环查找,如果没找到,则将当此循环的数组元素和下标插入,插入一次后哈希表有一个元素,下一次循环从上一轮插入后的哈希表中搜索,如果又没找到,又再插入,才有两个元素,最坏的情况是,数组最后两个元素满足要求,则最后一次循环时,哈希表元素个数才是 n-1 个。即相对写 Python 代码的那个思路,每次循环都从 n 个元素里搜索处理量更小一点,总体上对于哈希查找差异其实并不是很大。