最近更新于 2024-05-05 14:19
Linux 是一种动态系统,能够适应不断变化的计算需求。Linux 计算需求的表现是以进程的通用抽象为中心的,进程可以是短期的(比如执行一个命令),也可以是长期的(比如网络服务器之类的长期后台运行),因此,对进程及其调度进行一般管理就显得极为重要。
进程相关基础概念
进程
Linux 是一个多任务的操作系统,也就是说,在同一个时间内,可以有多个进程同时执行,如果读者对计算机硬件体系有一定了解的话,会知道我们大家常用的 CPU 单个核心实际上在一个时间片段内只能执行一条指令。那么 Linux 是如何实现多个进程同时执行的呢?Linux 使用了一种叫做“进程调度”(Process Scheduling)的手段,首先,为每个进程指派一定的运行时间,这个时间通常很短,短到以毫秒为单位计算,然后依照某种规则,从众多进程中挑选一个投入运行,其他的进程暂时等待,当正在运行的那个进程时间耗尽,或执行完毕退出,或因某种原因暂停,Linux 就会重新进行调度,挑选下一个进程投入运行。因为每个进程占用的时间片都很短,从我们使用者的角度来看,就好像多个进程同时运行一样。
在 Linux 中,每个进程在创建时都会被分配一个数据结构,称为进程控制块(Process Control Block,PCB)。PCB 中包含了很多重要的信息,供系统调度和进程本身执行使用,其中最重要的莫过于进程 ID(Process ID),进程 ID 也被称为进程标识符,是一个非负的整数,在 Linux 操作系统中唯一地标志一个进程。其实从进程 ID 的名字就可以看出,它就是进程的 “身份证号码”,每个进程的进程 ID 也不会相同。
进程的分类
进程一般分为交互进程、批处理进程和守护进程 3 类。
值得一提的是守护进程总是活跃的,一般是后台运行的。守护进程一般是由操作系统在开机时通过脚本自动激活启动或由超级管理用户 root 来启动的。由于守护进程是一直运行着的,所以它所处的状态是等待处理任务的请求。
进程的属性
- 进程 ID (PID)是唯一的数值,用来区分进程。
- 父进程和父进程 ID (PPID)。
- 启动进程的用户 ID (UID)和所属归属的组(GID)。
- 进程状态分为运行(R)、休眠(S)和僵尸(Z)。
- 进程执行的优先级。
- 进程所连接的终端名。
- 进程资源占用。
父进程和子进程
父进程和子进程的关系是管理和被管理的关系,当父进程终止时,子进程也随之而终止;但子进程终止,父进程并不一定终止。比如,当 httpd 服务器运行时,我们可以杀掉其子进程,父进程并不会因为子进程的终止而终止。
在进程管理中,当我们发现占用过多或无法控制的进程时,应该杀死它,以保证系统安全运行。
Linux 进程管理
监视进程的工具:ps
参数:
l 长格式输出。
u 按用户名和启动时间顺序来显示进程。
j 用任务格式来显示进程。
f 用树状格式来显示进程。
a 显示所有用户的所有进程。
x 显示无控制终端的进程。
r 显示运行中的进程。
常用组合一般是 aux 或 lax,输出内容解释:
USER 进程的属主.
PID 进程的 ID.
PPID 父进程的 ID。
%CPU 进程的 CPU 占用。
%MEM 进程的内存占用。
NI 进程的 NICE 值,数值越大,表示较少占用 CPU 时间。
VSZ 进程虚拟大小。
RSS 驻留中页的数量。
TTY 终端 ID。
STAT 进程状态。
D 不可中断。
R 正在运行或在队列中的进程。
S 处于休眠状态。
T 停止或被追踪。
X 死掉的进程。
Z 僵尸进程。
< 优先级高的进程。
N 优先级较低的进程。
L 有些页被锁进进程。
s 进程的领导者(其下有子进程)。
l 多进程(使用 CLONE_THREAD,类似 NPTL)
+ 位于后台的进程组。
WCHAN 正在等待的进程资源。
START 启动进程的时间。
TIME 进程消耗 CPU 的时间。
COMMAND 命令的名称和参数。
查询进程的工具:pgrep
pgrep 是通过程序的名字来查询进程的工具,一般用来判断程序是否正在运行。在服务器的配置和管理中,这个工具常被应用,简单明了。常用参数:
-l 列出程序名和进程 ID。
-o 进程起始的 ID。
-n 进程终止的 ID。
中止进程的工具:kill、killall、pkill 和 xkill
1.kill 函数
kill 函数一般是和 ps 或 pgrep 命令结合在一起使用的(获取 PID),用法格式:
kill 信号代码 进程ID
关于信号可以看shell 编程 (用 trap 命令捕捉信号)
2.killall 函数
killall 函数可以通过程序的名字直接杀死所有进程,用法格式:
killall 程序名
3.pkill
pkill 函数和 killall 函数应用差不多,也是直接杀死运行中的程序。
4.xkill
xkill 函数是在桌面上用于杀死图形界面的程序。例如,当某个图形程序出现崩溃不能退出时,单机鼠标就能将其杀死。
监视系统任务的工具:top
与 ps 相比,top 是动态监视系统任务的工具,top 输出的结果是连续的。
-b 以批量模式运行,但不能接收命令行输入。
-c 显示命令行,而不仅仅是命令名。
-d N 显示两次刷新时间的间隔,间隔时间为 N 秒。
-i 禁止显示空闲进程或僵尸进程。
-n N 显示更新次数(更新 N 次),然后退出。
-p PID 仅监视指定进程的 ID。
-q 不经任何延时就刷新。
-s 以安全模式运行,禁用一些交互指令。
-S 以积累模式运行,输出每个进程的总的 CPU 时间,包括已死的子进程。
常用的交互式命令键位如下:
space 立即更新。
c 切换到命令名显示,或显示整个命令。
f、F 增加显示字段,或删除显示字段。
h、? 显示有关安全模式和累积模式的帮助信息。
k 提示输入要杀死的进程 ID,目的是用来杀死该进程(默认信号 15)。
i 禁止空闲进程和僵尸进程。
l 切换到显示平均负载和正常运行时间等信息。
m 切换到内存信息,并以内存占用大小排序。
n 提示显示的进程数。
o、O 改变显示字段的顺序。
r 把 renice 应用到一个进程,提示输入 PID 和 renice 的值。
s 改变两次刷新的时间间隔,单位为秒。
t 切换到显示进程和 CPU 状态信息。
A 按进程生命大小进行排序,最新进程显示在最前面。
M 按内存占用大小排序,由大到小。
N 按进程 ID 大小排序,由大到小。
P 按 CPU 占用情况排序,由大到小。
S 切换到累计时间模式。
T 按时间/累计时间对任务进行排序。
W 把当前的配置写到 “~/.toprc”。
进程的优先级:nice 和 renice
在 Linux 操作系统中,进程之间是竞争资源的关系。这个竞争的结果是通过一个数值来体现的,也就是谦让度。高谦让度表示进程优先级别低。负值或 0 表示高优先级,对其它进程不谦让,也就是拥有优先占用系统资源的权利。谦让度的值为 -20 ~ 19。
目前硬件技术发展迅速,在大多情况下,不必设置进程的优先级,除非在进程失控而疯狂占用资源的情况下,我们有可能需要设置优先级,但没有太大的必要,在迫不得已的情况下,我们可以杀掉失控进程。
在创建进程时,nice 可以为进程指定谦让度的值,进程优先级的值是父进程 shell 优先级的值与我们指定的谦让值得相加结果。所以我们在用 nice 设置程序得优先级时,所指定的数值是一个增量,并不是优先级的绝对值。
nice -n 谦让度的增量值 程序
renice 所设置的就是进程的绝对数值
renice 谦让度 PID
Linux 进程的三态
三种基本状态
(1)就绪(Ready)状态。若进程已被分配到除 CPU 以外所有必要地资源,只要获得处理器便可立即执行,这时的进程状态称为就绪状态。
(2)运行(Running)状态。当进程已获得处理器,其程序正在处理器上执行,此时的进程状态称为运行状态。
(3)阻塞(Blocked)状态。当正在执行的进程,由于等待某个事件发生而无法执行时,便处于阻塞状态。引起进程阻塞的事件可能有多种,例如等待 I/O 完成、申请缓冲区不能满足、等待信号等。
三种状态间的转换
一个进程在运行期间,会不断地从一种状态转换到另一种状态,它可能多次多次处于就绪状态和执行状态,也可以多次处于阻塞状态。

(1)就绪->运行。处于就绪状态地进程,当进程调度程序为之分配了处理器后,该进程便由就绪状态变成运行状态。
(2)运行->就绪。处于运行状态地进程在其运行过程中,因分配给它的一个时间片段已用完而不得不让出 CPU,于是进程从运行状态转变成就绪状态。
(3)运行->挂起。当正在执行的进程因等待某种事件发生而无法继续执行时,便从运行状态变成挂起状态。
(4)挂起->就绪。处于挂起状态的进程,若其等待的事件已经发生,便由挂起状态转变为就绪状态。
Linux 进程结构
参看内存管理(数据存放)
Linux 进程控制块(PCB)
Linux 的进程控制块是一个由结构体 task_struct 所定义的数据结构,task_struct 放在 /usr/include/linux/sched.h 中,包括管理进程所需的各种信息。Linux 系统的所有进程控制块组织成结构数组的形式。
在创建一个新进程时,系统在内存中申请一个空的 task_struct 区,即空闲 PCB 块,并填入所需的信息,同时将指向该结构的指针填入到 task[] 数组中。当前处于运行状态的 PCB 用指针数组 “current_set[]” 来指出。系统内可能存在多个同时运行的进程,故将 current_set 定义成指针数组。
Linux 系统的 PCB 包括很多参数,每个 PCB 约占 1KB 的内存空间。用于表示 PCB 的结构 task_struct 简要描述:
struct task_struct
{
...
// 用户标识
unsigned short uid;
// 进程标识
int pid;
// 标识用户正在使用的 CPU,以支持对称多处理器的方式
int processor;
...
// 标识进程的状态,可为下列6种状态之一
// 可运行状态:TASK-RUNING
// 可中断阻塞状态:TASK-UBERRUPTIBLE
// 不可中断阻塞状态:TASK-UNINTERRUPTIBLE
// 僵死状态:TASK-ZOMBLE
// 暂停态:TASK-STOPPED
// 交换态:TASK-SWAPPING
volatile long state;
// 进程的优先级
long prority;
// 实时进程的优先级,对普通进程无效
unsigned long rt_prority;
// 为进程动态优先级计数器,用于进程轮转调度算法
long counter;
// 进程调度策略,其值为以下3种之一
// SCHED_OTHER (0) 对应普通进程优先级轮转法(round robin)
// SCHED_FIFO (1) 对应实时进程先进先服务算法
// SCHED_RR(2)对应实时进程优先级轮转法
unsigned long policy;
...
// 进程 PCB 双向链表的前后项指针
struct task_struct *next_task, *prev_task;
// 就绪队列双向链表的前后项指针
struct task_struct *next_run, *prev_run;
// 指明进程家族间的关系,分别指向祖父进程、父进程、子进程以及新老进程的指针
struct task_struct *p_opptr, *p_pptr, *p_cptr, *pysptr, *p_ptr;
}
Linux 进程调度
在多进程、多线程并发的环境里,从概念上看,有多个进程或者多个线程在同时执行,具体到单个 CPU,实际上任何时刻只能有一个进程或者线程处于执行状态。因此 OS 需要决定哪个进程执行,哪些进程等待,也就是进程的调度。
调度的目标
进程使用 CPU 分为 3 种模式:I/O密集型、计算密集型和平衡型。对于 I/O 密集型程序来说,响应事件非常重要;对于计算密集型程序来说,CPU 的周转时间就比较重要;对于平衡型程序来说,响应和周转之间的平衡是最重要的。
CPU 的调度就是要达到极小化平均响应时间、极大化系统吞吐率、保持系统各个功能部件均处于繁忙状态和提供某种公平的机制。
对于实时系统来说,调度的目标就是要在达到截止时间前完成所有应该完成的任务和提供性能的可预测性。
调度算法
1.FCFS
FCFS(First Come First Serve——,也称为为 FIFO 算法,先来先处理。这个算法的优点是简单,实现容易,并且似乎公平;缺点在于短的任务有时候可能变得非常慢,因为其前面的任务占用很长时间,造成了平均响应时间非常长。
2.时间片轮询算法
该算法是对 FIFO 算法的改进,目的是改善短程序(运行时间短)的响应时间,其方法就是周期性地进行进程切换。这个算法的关键点在于时间片的选择,时间片过大,那么轮转就越接近 FIFO;如果时间片太小,则进程切换的开销大于执行程序的开销,从而降低系统效率。因此选择合适的时间片就非常重要。选择时间片的两个需要考虑的因素:① 一次进程切换所使用的系统消耗。② 我们能接受的整个系统消耗、系统运行的进程数。
时间片轮询算法看上去非常公平,并且响应时间非常好,然而时间片轮转并不能保证系统的响应时间总是比 FiFO 算法短,这很大程度上却决于时间片大小的选择以及这个大小与进程运行时间的相互关系。
3.STCF
STCF(Short Time to Complete First)算法,顾名思义就是短任务优先算法。这种算法的核心就是所有的进程都有一个优先级,短任务的优先级比长任务的高,而 OS 总是安排优先级高的进程先运行。
STCF 又分为非抢占式和抢占式两类。非抢占式 STFC 就是让已经在 CPU 上运行的程序执行到结束或者阻塞,然后在所有的就绪进程中选择执行时间最短的来执行;而抢占式 STCF 则不是这样,在每进来一个新的进程时,就对所有进程(包括正在 CPU 上执行的进程)进行检查,谁的执行时间短,就运行谁。
STCF 总是能提供最优的响应时间,然而它也有缺点:① 可能造成长任务的程序无法得到 CPU 时间而饥饿,因为 OS 总是优先执行短任务;② 关键问题在于我们怎么知道程序的运行时间,怎么预测某个进程需要的执行时间,通常有两个办法,使用启发式方法估算(如根据程序的大小估算),或者将程序执行一遍后记录其所用的 CPU 时间,在以后的执行过程中就可以根据这个数据清单来进行 STCF 调度。
4.优先级调度
STCF 遇到的问题是长任务的程序可能饥饿,那么优先级调度算法可以通过给长任务的进程更高的优先级来解决这个问题;优先级调度遇到的问题也可能是短任务的进程饥饿,这个可以通过动态调整优先级来解决。实际上动态调整优先级(称为权值)+ 时间片轮询的策略正是 Linux 的进程调度策略之一 —— SCHED_OTHER 分时调度策略,它的调度过程如下。
(1)在创建任务时指定采用分时调度策略,并指定优先级的 nice 值(-20 ~ 19)。
(2)根据每个任务的 nice 值确定在 CPU 上的执行时间(counter)。
(3)如果没有等待资源,则将该任务加入就绪队列中。
(4)调度程序遍历就绪队列中的任务,通过对每个任务动态优先级的计算(counter + 20 – nice)结果,选择计算结果最大的一个去运行。当这个时间片用完以后(counter 减至 0)或者主动放弃 CPU 时,该任务将被放在就绪队列末尾(时间片用完)或等待队列(因等待资源而放弃 CPU)中。
(5)此时调度程序重复上面的计算过程,转至步骤(4)。
(6)当调度程序发现所有就绪任务计算所得的权值都为不大于 0 时,重复步骤(2)。
Linux 还有两个实时进程的调度策略:FIFO 和 RR。实时进程会立即抢占非实时进程。显然,没有什么调度算法是毫无缺点的,因此现代 OS 通常通常都会采用混合调度算法。例如,将不同的进程分为几个大类,每个大类有不同的优先级,不同大类的进程调度取决于大类的优先级,同一个大类的进程采用时间片轮询法来保证公平性。
5.其它调度算法
保证调度算法确保每个进程想用的 CPU 时间完全一样。彩票调度算法是一种概率调度算法,通过给进程“发彩票”,来赋予不同进程不同的调用时间,彩票调度算法的有点是非常灵活,如果给短任务发更多”彩票“,那么就类似 STFC 调度;如果给每个进程一样多的”彩票“,那么就类似于保障调度。用户公平调度算法,是按照每个用户,而不是按照每个进程来公平分配 CPU 时间的,这是为了防止贪婪用户启用了过多进程导致系统效率降低甚至停顿。
6.实时系统的调度算法
实时系统需要考虑每个具体任务的响应时间必须符合要求,在截止时间前完成任务。
最早截止任务优先(Earliest Deadline First,EDF)算法,也就是让最早截止的任务先运行。当新的任务过来时,如果它的截止时间更靠前,那么就让新任务抢占正在运行的任务。EDF 算法实际是贪心算法的一种体现。如果一组任务可以被调度(也就是说所有任务的截止时间在理论上都可以得到满足),那么 EDF 可以全部满足;如果一批任务不能全部满足(全部在各自的截止时间前完成),那么 EDF 满足的任务数最多,这就是它的最优体现。EDF 实际就是抢占式 STCF,只不过将程序的执行时间换成了截止时间。EDF 的缺点在于需要对每个任务的截止时间进行计算并动态调整优先级,并且抢占任务也需要消耗系统资源,因此它的实际效果比理论预想要差一点。
EDF 是动态调度算法,而 RMS(Rate Monotonic Scheduling)算法是一种静态最优算法,该算法在进行调度前先计算出所有任务的优先级,然后按照计算出来的优先级进行调度,在任务执行过程中既不接收新任务,也不进行优先级调整或者 CPU 抢占,因此它的有点是资源消耗小,缺点就是不灵活。对于RMS 算法,关键点在于判断一个任务组是否能够被调度,这里有一个定律,如果一个系统的所有任务的 CPU 利用率都低于 ln2(约等于 0.693147),那么这些任务的截止时间都可以得到满足.就是此时系统还剩下 30% 的 CPU 时间,这个证明是 Liu 和 Kayland 在 1973年给出的。
优先级反转
1.概念
优先级反转是指一个低优先级的任务持有一个被高优先级任务所需要的共享资源,高优先级任务由于资源缺乏而处于受阻状态,一直等到低优先级任务释放资源为止。而低优先级获得的 CPU 时间少,如果此时有优先级处于两者之间的任务,并且不需要那个共享资源,则该中优先级任务反而超过这两个任务而获得 CPU 资源。如果高优先级任务等待资源时不是阻塞等待,而是忙循环,则可能永远无法获得资源,因为此时低优先级进程无法与高优先级进程争夺 CPU 资源,从而无法执行,进而无法释放资源,这样造成的后果就是高优先级任务无法获得资源继续运行。
2.解决方案
(1)设置优先级上限,给临界区一个高优先级,进入临界区的进程都将获得这个高优先级,如果其它试图进入临界区的进程的优先级都低于这个高优先级,那么优先级反转就不会发生。
(2)优先级继承,当一个高优先级进程等待一个低优先级进程持有的资源的时候,低优先级进程将暂时获得高优先级进程的优先级别。在释放共享资源后,低优先级进程回到原来的优先级别。
嵌入式系统 VxWorks 就是采用的这种策略。1997年,美国的火星探测器(使用 VsWorks)就遇到一个优先级反转问题引起的故障。简单说下,火星探测器有一个信号总线,有一个高优先级的总线任务负责总线数据的存取,访问总线都需要都过一个互斥锁(共享资源);还有一个低优先级的,运行不是很频繁的气象搜集任务,它需要对总线写数据,也就同样需要访问互斥锁;最后还有一个中优先级的通信任务,它的运行时间比较长。平时这个系统运行毫无问题,但是有一天,在气象任务获得互斥锁准备往总线写数据的时候,一个中断发生导致通信任务被调度为就绪状态,通信任务抢占了低优先级的气象任务。而恰巧,此时高优先级的总线任务正在等待气象任务写完数据释放互斥锁,但是由于通信任务抢占了 CPU 并且运行时间比较长,导致气象任务得不到 CPU 时间也无法释放互斥锁,本来是高优先级的总线任务也无法执行,总线任务无法被及时执行被探索者号认为是一个严重错误,最后就是整个系统被迫重启。本来 Vsworks 允许优先级继承,然而工程师没有启用。
使用中断禁止,通过禁止中断来保护临界区,采用此种策略的系统只有两种优先级:可抢占优先级和中断禁止优先级。前者为一般进程运行时的优先级,后者为运行于临界区的优先级。火星探路者正是由于在临界区中运行的气象任务被中断发生的通信任务所抢占才导致故障,如果有临界区的禁止中断保护,这一问题也不会发生。
进程创建
获取进程
每一个进程都有一个 ID,可以通过调用 getid() 函数得到当前进程的 ID,而 getppid() 则可以得到当前进程的父进程(创建当前进程的进程)的 ID。
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief 获取进程信息
*/
#include <stdio.h>
#include <unistd.h>
int main(void)
{
printf("当前进程的ID:%d\n当前进程的父进程ID:%d\n", getpid(), getppid());
}
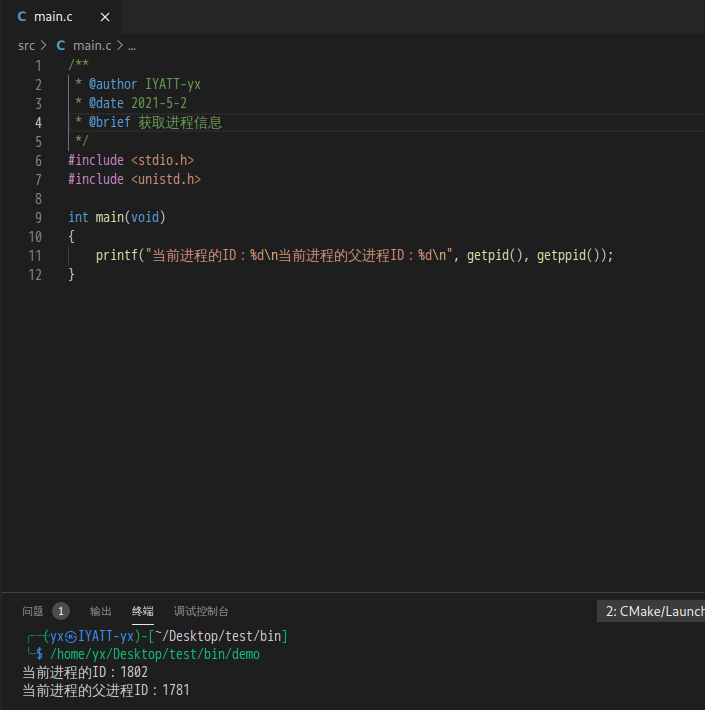
创建进程 fork
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief 进程创建示例
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void)
{
// 创建子进程
pid_t pid = fork();
// 根据返回值区分,分别为父子进程分配任务
if (pid == 0)
{
printf("我是子进程\t我的进程ID是:%d\t我的父进程ID是:%d\n", getpid(), getppid());
}
else if (pid > 0)
{
printf("我是父进程\t我的进程ID是:%d\t我的子进程ID是:%d\n", getpid(), pid);
}
else
{
printf("创建子进程失败!\n");
}
}
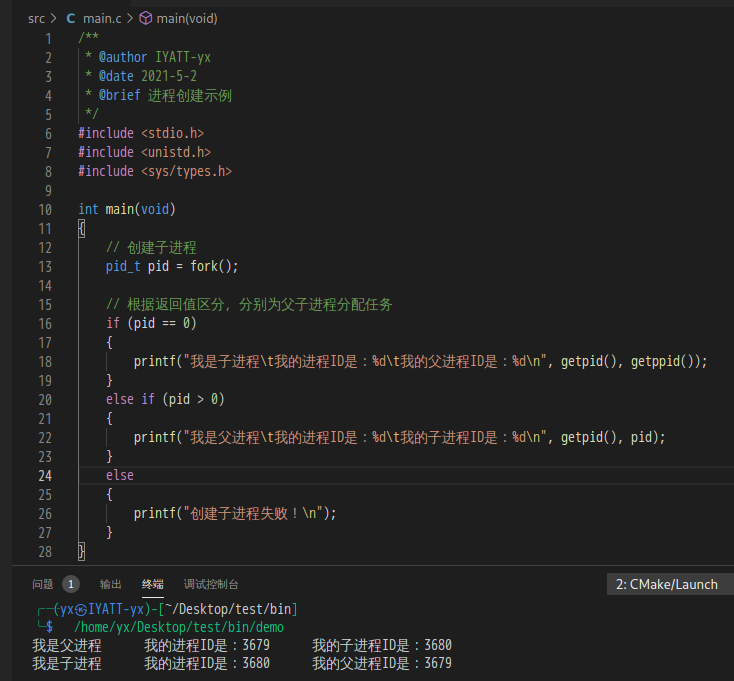
在使用 fork 函数创建一个进程时,子进程只是完全复制父进程的资源,除了各自有 task_struct 和 PID。例如,要是父进程打开了5个文件,那么子进程也有5个打开的文件,而且这些文件的当前读写指针也停留在相同的地方,所以,这一步所做的是复制。这样得到的子进程独立于父进程,具有良好的并发性,但是二者之间的通信需要通过专门的通信机制(比如,pipe、共享内存和信号等)。另外通过 fork 函数创建出一个子进程后,其子进程仅仅是为了调用 excl 执行另外一个可执行文件,那么在创建过程中对于虚拟空间的复制将是一个多余的过程。不过,现在的 Linux 中采用了 copy-on-write(COW,写时复制)技术,为了降低开销,fork 函数最初并不会真正产生两个不同的复制,因为在那么时候,因为在那个时候,大量数据其实完全是一样的。写时复制时在推迟真正的数据复制。若后来确实发生了写入,那意味着父进程和子进程的数据不一致了,于是产生复制动作,每个进程拿到属于自己的那一份,这样就可以降低系统调用的开销。
fork 函数每调用执行一次返回两个值,对于父进程,返回的是子进程的 PID,对于子进程,则返回 0。
在 fork 后,子进程和父进程都会继续执行 fork 函数之后的指令。子进程是父进程的副本,它将获得父进程的数据空间、堆和栈的副本,父子进程并不共享这一部分内存。也就是说,子进程对父进程中同名变量进行修改并不影响其父进程中的值。但是父子进程又共享一些东西,简单来说就是 .text 段,这部分存放着由 CPU 执行的机器指令,通常是只读的。
创建进程 vfork
用法和 fork 同,但是效果有所不同。用 vfork 创建的子进程与父进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,如果对子进程修改了某个变量,将会影响到父进程。
但是有一点需要注意,用 vfork 创建的子进程必须使用 exit() 来结束,否则子进程将不能结束,而 fork 不存在这个情况。
替换进程的代码 exec族
exec 族一共有 6 个函数,其中只有 execve 是真正意义上的系统调用,其他都是在其基础上封装的。
exec 族的作用是根据指定的文件名找到可执行文件,并用它来取代调用者的代码内容。即,在调用者内部执行另外一个可执行文件,这里的可执行文件既可以是二进制文件也可以是任何可执行的脚本文件。
与一般情况不同,exec 族函数执行成功后不会返回,因为调用进程的实体,包括代码段、数据段和堆栈等都已经被新的内容取代,只有进程 ID 等一些表面上的信息仍保持原样。只有当调用失败时,才会返回 -1,从原程序的调用点接着往下执行。
一般当一个进程想要执行另外一个程序的时候,它就可以通过 fork 函数创建出一个新的进程,然后调用 exec 族函数,这样看起来就好像通过执行应用程序而产生了一个新的进程。
Linux 也专门为其做了优化,fork 函数会将父进程的内容原封不动地复制到新进程当中,这些复制地动作十分耗时,而如果创建子进程后立即又调用 exec,这些辛辛苦苦复制来地东西又会被立即抹除,这看起来就是做了无用功,于是就有了 COW (前面已经提过)技术,使得在创建进程后并不会立即复制父进程地内容,而是等到真正需要使用地时候才复制,这样就可以避免白白做无用功,提高了效率。
execl用于执行文件
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief execl 示例
*/
#include <stdio.h>
#include <unistd.h>
int main(void)
{
// execl用于执行文件
// 第一个参数为可执行文件的绝对路径
// 第二个参数占位,随便写什么都行,我一般留空字符串
// 第三个及以后的参数个数不限,作为执行文件的参数
// 结尾必须是 NULL
execl("/bin/ls", "", "-al", "/", NULL);
// execl 执行出错返回 -1,error被设置为相应的错误值(使用perror可以直接显示错误)
// 但是这里并不需要判断返回值
// 因为一旦 execl 执行成功,那么当前进程后面的语句就不会再被执行,而只有调用失败才会继续执行后面的语句,所以不需要判断返回值
perror("execl error");
}
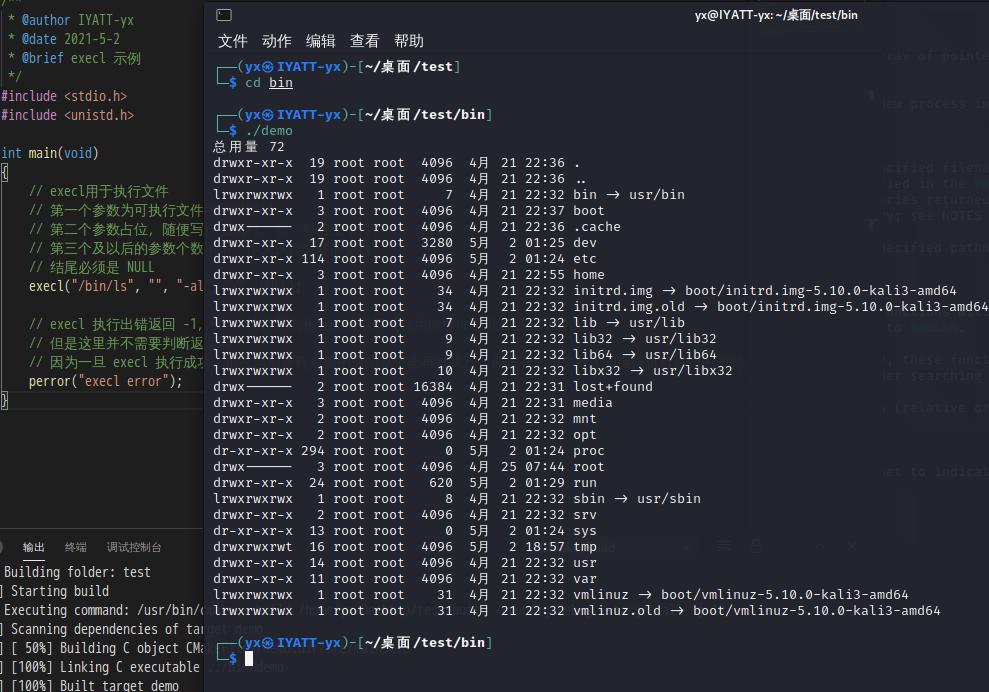
execlp 用于从 PATH 环境变量中查找文件并执行,用法同 execl
exec 族其它函数可以使用 man 自己查询,上面两个是最常用的。
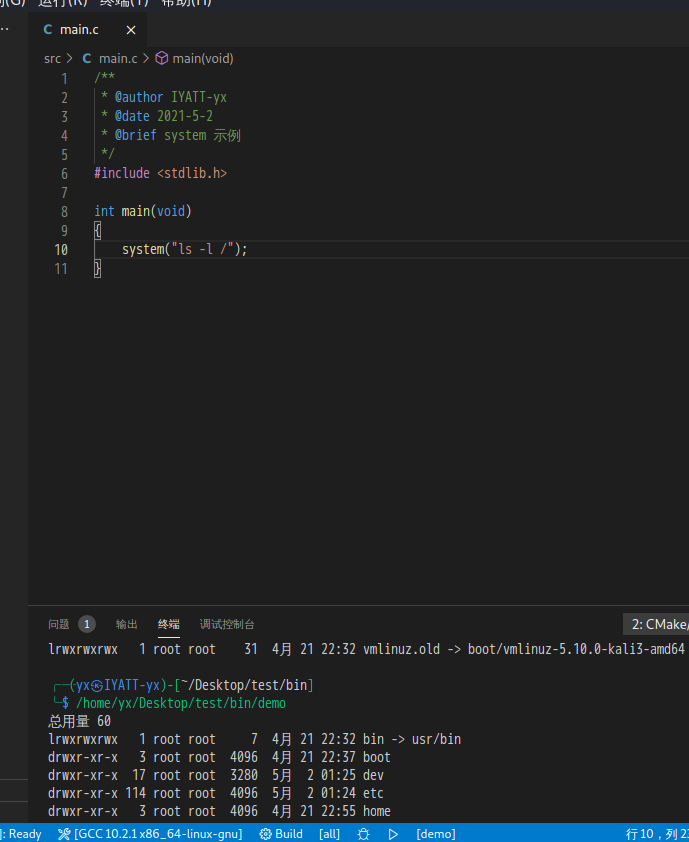
执行 shell 命令 system
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief system 示例
*/
#include <stdlib.h>
int main(void)
{
system("ls -l /");
}
进程等待
僵尸进程的概念
僵尸进程就是已经结束了的,但是还没有从进程表中删除的进程。僵尸进程过多会导致进程表里条目被填满,进而导致系统崩溃。
在进程的状态中,僵尸进程是非常特殊的一种,它已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息供其它进程收集。除此之外,不再占用任何内存空间。
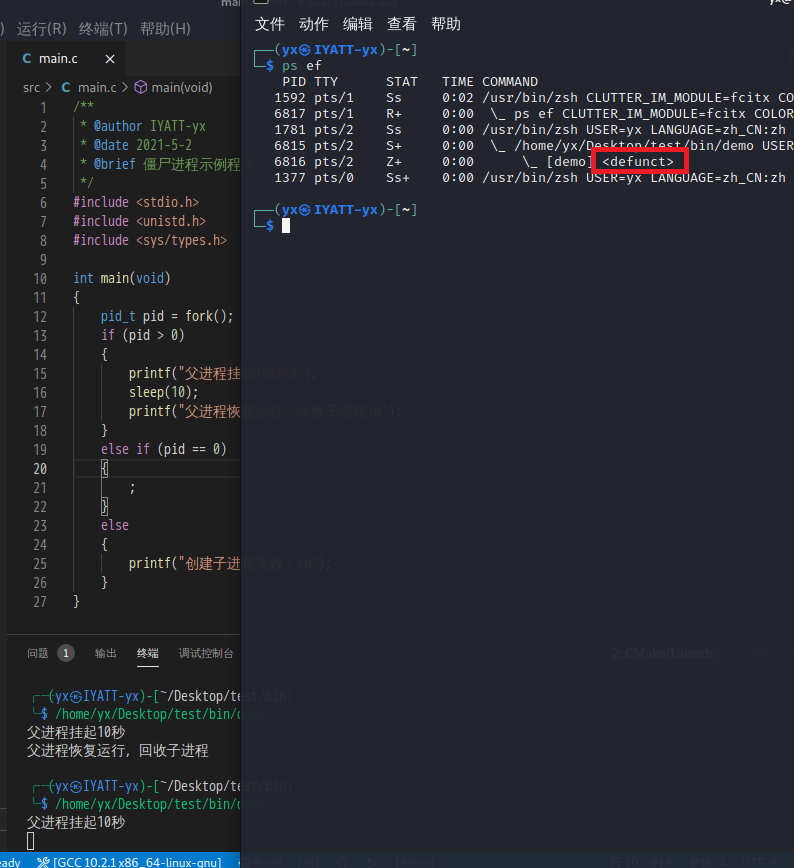
子进程执行完以后只能由父进程回收,而有时候父进程一直在忙于执行任务,此时子进程运行完了,但是因为父进程一直忙碌中,没法回收子进程,这时候原来的子进程就是一个僵尸进程了。可以通过 ps ef 查看,标识有 <defunct>
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief 僵尸进程示例程序
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void)
{
pid_t pid = fork();
if (pid > 0)
{
printf("父进程挂起10秒\n");
sleep(10);
printf("父进程恢复运行,回收子进程\n");
}
else if (pid == 0)
{
;
}
else
{
printf("创建子进程失败!\n");
}
}
如何避免僵尸进程
如果父进程很忙,那么可以使用 signal 捕捉 子进程结束运行的型号,然后立即回收。
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief 解决僵尸进程示例程序
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include <sys/wait.h>
/**
* @brief 回收子进程
* @param signo signal函数要求的回调函数的参数,用于传入捕捉到的信号值
*/
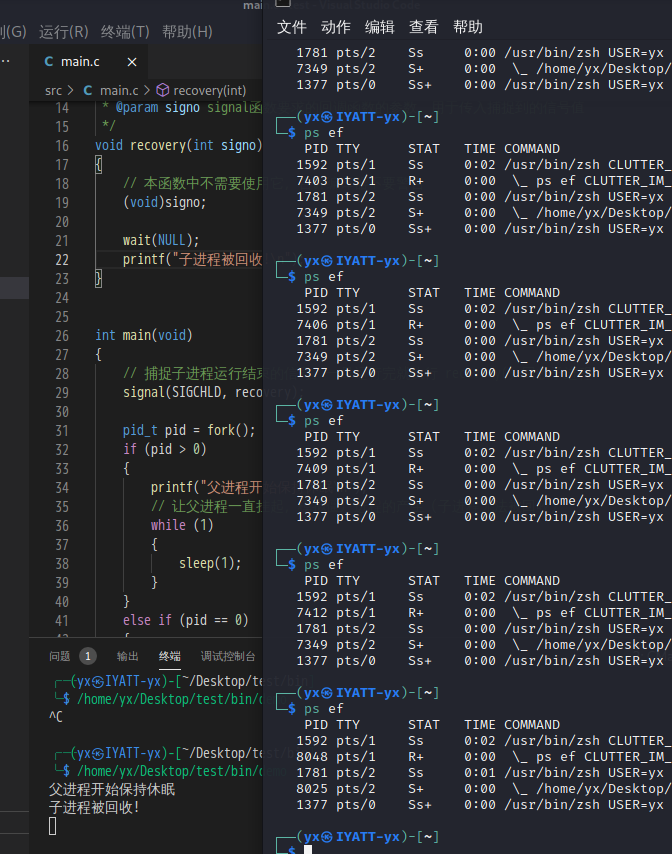
void recovery(int signo)
{
// 本函数中不需要使用它,告诉编译器不要警告
(void)signo;
wait(NULL);
printf("子进程被回收!\n");
}
int main(void)
{
// 捕捉子进程运行结束的信号,一旦运行完就执行 recovery() 回收子进程
signal(SIGCHLD, recovery);
pid_t pid = fork();
if (pid > 0)
{
printf("父进程开始保持休眠\n");
// 让父进程一直挂起,模拟僵尸进程的产生(子进程无法被回收)
while (1)
{
sleep(1);
}
}
else if (pid == 0)
{
;
}
else
{
printf("创建子进程失败!\n");
}
}
如果父进程不关心子进程什么时候结束,那么可以用 signal 通知内核,自己对子进程结束并不关心,则子进程结束后会被内核回收,并不再给父进程发送信号。
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief 让内核回收子进程
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include <sys/wait.h>
int main(void)
{
// 捕捉子进程运行结束的信号,一旦运行完就让内核来回收子进程
signal(SIGCHLD, SIG_IGN);
pid_t pid = fork();
if (pid > 0)
{
printf("父进程开始保持休眠\n");
// 让父进程一直挂起,模拟僵尸进程的产生(子进程无法被回收)
while (1)
{
sleep(1);
}
}
else if (pid == 0)
{
;
}
else
{
printf("创建子进程失败!\n");
}
}
孤儿进程
父进程先执行完结束了自己,而子进程还在运行,此时子进程为孤儿进程,init进程(进程ID为:1,它是内核启动的第一个用户级进程)将继承成为其父进程,然后由其释放子进程。
不过在创建守护进程的时候,反而是故意要创建的孤儿进程,后面详谈。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void)
{
pid_t pid = fork();
if (pid == 0)
{
// 把子进程挂起,让父进程先死
printf("我的父亲是:%d\n", getppid());
sleep(3);
printf("我醒了,爹咋不见?\n");
printf("我的继父是:%d\n", getppid());
}
else if (pid > 0)
{
// 比子进程先死就行
sleep(1);
}
else
{
printf("进程创建失败!\n");
}
}

上面运行结果的现象可能有些奇怪,因为父进程先结束,而只要父进程结束了,系统就认为这个程序结束了,重新回到命令提示符。而子进程此时还在运行,打印输出东西就会显示在命令提示符后面。
wait 和 waitpid
用于等待子进程中断或结束。
像上面的孤儿进程的问题就可以使用这两个函数来应对,当父进程的任务执行完而子进程还在运行的情况下,会将父进程挂起等待,直到子进程任务结束,将其回收之后才结束父进程。
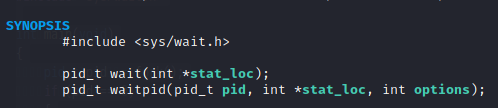
wait() 会暂停当前进程的执行,直到有信号来到或子进程结束为止。如果在调用 wait() 时子进程已经结束,则 wait() 会立即返回子进程结束状态值。子进程的结束状态值会由参数 stat_loc 返回,而子进程的进程PID作为返回值返回。如果不在意结束状态值,stat_loc 可以设置为 NULL。子进程的结束状态值同 waitpid 。
waitpid() :
pid:
pid < -1 等待 pgid(进程组ID)为 pid 绝对值的任何子进程;pid == -1 等待任何进程(同 wait);pid = 0 等待 pgid 和当前进程相同的任何子进程。pid > 0 等待任何子进程PID为 pid 的子进程。
stat_loc:
WIFEXITED(stat_loc) 如果子进程正常结束则为非0值。
WEXITSTATUS(stat_loc) 取得子进程 exit()返回的结束代码,一般会先用 WIFEXITED 来判断子进程是否正常结束,正常结束才使用此宏。
WIFSIGNALED(stat_loc) 如果子进程是因为信号而结束的,则为真。
WTERMSIG(stat_loc) 取得子进程因信号而终止的信号代码,一般先用 WIFSIGNALED 进行判断后才使用此宏。
WIFSTOPPED(stat_loc) 如果子进程处于暂停执行状态,则为真。
WSTOPSIG(stat_loc) 取得引发子进程暂停的信号代码,一般会先用 WIFSTOPPED 判断。
options:
0 等待子进程结束
WNOHANG 如果没有任何已经结束的进程则马上返回,不予等待。
WUNTRACED 如果子进程进入暂停执行状态则马上返回,但结束状态不予理会。
/**
* @author IYATT-yx
* @date 2021-5-2
* @brief wait回收进程示例
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void)
{
pid_t pid = fork();
if (pid == 0)
{
// 把子进程挂起,让父进程先死
printf("父进程是:%d\n", getppid());
sleep(3);
printf("父进程是:%d\n", getppid());
}
else if (pid > 0)
{
// 比子进程先死就行
sleep(1);
// 等待回收子进程
wait(NULL);
}
else
{
printf("进程创建失败!\n");
}
}
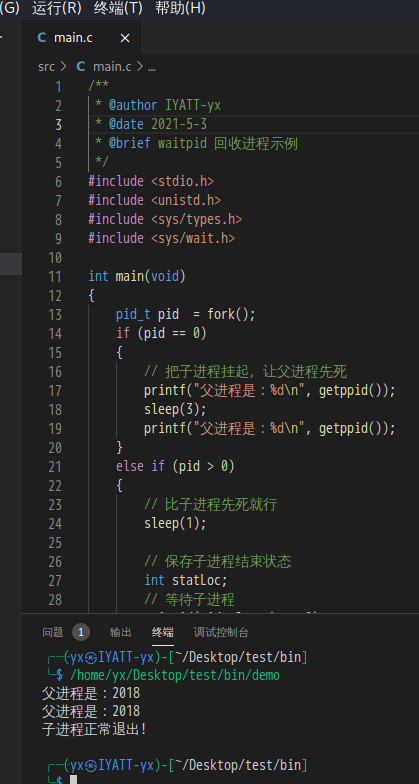
/**
* @author IYATT-yx
* @date 2021-5-3
* @brief waitpid 回收进程示例
*/
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main(void)
{
pid_t pid = fork();
if (pid == 0)
{
// 把子进程挂起,让父进程先死
printf("父进程是:%d\n", getppid());
sleep(3);
printf("父进程是:%d\n", getppid());
}
else if (pid > 0)
{
// 比子进程先死就行
sleep(1);
// 保存子进程结束状态
int statLoc;
// 等待子进程
waitpid(pid, &statLoc, 0);
// 判断子进程结束状态
if (WIFEXITED(statLoc))
{
printf("子进程正常退出!\n");
}
else
{
printf("子进程非正常退出!\n");
}
}
else
{
printf("进程创建失败!\n");
}
}
进程退出
在 Linux 中,进程退出标识进程即将结束。在 Linux 中进程退出分为正常退出和异常退出两种。
正常退出:
在 main 中执行 return;
调用 exit 函数;
调用 _exit 函数。
异常退出:
调用 abort 函数;
进程收到某个信号,该信号使进程终止。
不管哪种退出方式,系统最终都会执行内核中的同一段代码,这段代码用来关闭进程所有已打开的文件描述符,释放它所占用的内存和其它资源。
比较区别:
exit 和 return:前者是一个函数,有参数,exit 执行后将控制权交給系统;后者是函数执行完后的返回,return 执行完后把控制权交给调用函数。
exit 和 abort:前者是正常中止进程;后者是异常终止进程。
exit 和 _exit:
exit 是在 _exit 基础上的封装,两者最大的区别是:exit 在调用 _exit 之前要检查文件的打开情况,把文件缓冲的内容写回文件。由于在 Linux 的标准函数库中,有一种被称为 “缓冲 I/O” 的操作,其特征就是对应每一个打开的文件,在内存中都有一片缓冲区。在每次读文件时,会连续地读入若干记录,这样在下次读文件时就可以直接从内存地缓冲区中读取;同样在每次写文件时也仅仅是写入内存的缓冲区,等满足了一定条件(达到一定数量或者遇到特定的字符等),再将缓冲区的内容一次性写入文件。这种技术大大增加了文件读写的速度,但也给开发带来了一定麻烦。
比如,有一些数据被认为已经写入了文件,实际上因为没有满足特定条件,他们还只是保存在缓冲区中,这时用 _exit 直接将进程关闭,则缓冲区内的数据会丢失。因此如果想保证数据的完整性,就一定要使用 exit 函数。
守护进程
守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生地事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux 系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程 syslogd、Web 服务器 httpd 和数据库服务器 mysqld 等。
守护进程一般在系统启动时开始运行,除非强行终止,否则直到系统关机都保持运行。守护进程经常以超级用户(root)权限运行,因为它们要使用特殊的端口(1~1024)或访问某些特殊的资源。
守护进程的父进程是 init 进程(PID为 1,内核启动的第一个用户级进程),因为它真正的父进程在创建出子进程后就退出了,所以守护进程是一个由 init 继承的孤儿进程。守护进程是非交互式程序,没有控制终端,所以任何输入,无论是向标准输出设备 stdout 还是标准出错设备 stderr 的输出都需要经过特殊处理。
守护进程的名称通常以 d 结尾,如 sshd、xinetd 和 httpd等等。
| 特点 | 后台服务进程 独立于控制终端 周期性执行某任务 不受用户登录注销影响 一般采用以 d 结尾的名字 (服务) |
| 进程组 | 组长:第一个进程 进程组ID:组长的ID |
| 会话期 (一个或多个进程组的集合) | 创建会话: * 不能是进程组长 * 创建会话的进程成为新进程组的组长 * 部分Linux发行版需要root * 创建出的新会话会丢弃原有的控制终端 * 一般步骤:fork() 创建子进程,父进程死,子进程执行创建会话操作 创建会话:setsid() 获取所属会话ID:getsid() |
| 创建守护进程的模型 | 1.fork()子进程,父进程退出。 fork 创建子进程,并让父进程退出,shell 就会认为程序执行完毕,此时子进程(孤儿进程)保持运行,能够继续执行任务,程序初步脱离终端。 2.子进程调用 setsid() 创建新会话。 新创建的子进程全盘复制了父进程的会话期、进程组和控制终端等,虽然父进程退出了,但是会话期、进程组和控制终端等并没有改变,还不是真正意义上的独立,而 setsid 函数可以让进程完全独立出来。 3.再次创建子进程,并让父进程退出。 第一次创建的子进程虽然已经成为无终端的会话组长,但它可以重新申请打开一个终端。则可以在这个进程内再次使用 fork 创建一个子进程,并退出当前进程(第一次创建的子进程),第二次创建的子进程不是会话首进程,这个进程将不能重新打开控制终端。 4.更改当前工作目录到 “/” 使用 fork 函数创建的子进程继承了父进程的工作目录,而进程运行中可能会发生更改(比如这个程序是在U盘上启动的,拔掉U盘后这个路径就不存在了)。通常的做法是让 “/” (根)作为守护进程的工作目录(使用 chdir 函数),这样就能避免产生问题。 5.重设文件掩码为 0。 文件权限掩码用于屏蔽文件权限中的对应位,但是这会给进程使用造成麻烦。比如,在进程中本来想创建一个有读、写和执行权限的文件,结果文件掩码屏蔽了执行权限,则不能直接指定创建含有执行权限的文件。而将文件权限掩码设置为 0,则进程想创建什么权限的文件,创建出来就是什么权限。(使用 umask 函数) 6.关闭文件描述符。 创建的子进程可能从父进程那里继承了一些已经打开的文件,这些被打开的文件永远不会被守护进程读写,但它们会消耗系统资源,而且可能导致所在的文件系统无法卸载。 在(2)步骤以后,守护进程已经与所属的终端失去了联系。因此从终端输入的字符不可能被读取到,同样也无法向终端输出显示。则标准输入、输出和错误这3个自动打开的文件已经没有了价值,应该关闭。(使用 close 函数) 7.守护进程的核心工作。 创建这个守护进程必然有需要做的事,这个就是根据自己的需要来写了。 8.守护进程退出处理。 当用户需要从外部停止守护进程运行时,往往会使用 kill 命令。所以需要在进程中实现 kill 发出信号处理,实现进程的正常退出。 |
/**
* @author IYATT-yx
* @date 2021-5-3
* @brief 守护进程示例 - 每隔两秒记录一次系统时间并写入 /tmp/daemon.log
*/
#define _POSIX_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <stdbool.h>
#include <stdlib.h>
#include <signal.h>
#include <time.h>
#include <string.h>
#include <fcntl.h>
// 用于守护进程是否停止运行的标志
bool g_flag = true;
/**
* @brief 收到 QUIT 信号就修改 g_flag 标志 - 回调函数
* @param sig 传入捕获到的信号值
*/
void changeFlag(int sig)
{
(void)sig;
g_flag = false;
}
/**
* @brief 创建守护进程
*/
void createDaemon(void)
{
// 第一次创建子进程
pid_t pid = fork();
if (pid == -1)
{
perror("fork error");
exit(EXIT_FAILURE);
}
else if (pid)
{
// 退出父进程
exit(EXIT_SUCCESS);
}
// 创建会话
if (setsid() == -1)
{
perror("setsid error");
exit(EXIT_FAILURE);
}
// 在第一次创建的子进程中再次创建新的子进程
pid = fork();
if (pid == -1)
{
exit(EXIT_FAILURE);
}
else if (pid)
{
exit(EXIT_SUCCESS);
}
// 修改工作目录
chdir("/");
// 关闭 stdin、stdout、stderr
for (int i = 0; i < 3; ++i)
{
close(i);
}
// 修改文件掩码
umask(0);
return;
}
int main(void)
{
createDaemon();
struct sigaction act;
act.sa_handler = changeFlag;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
if (sigaction(SIGQUIT, &act, NULL) == -1)
{
exit(EXIT_FAILURE);
}
while (g_flag)
{
int fd = open("/tmp/daemon.log", O_WRONLY | O_CREAT | O_APPEND, 0664);
time_t t = time(NULL);
char *buf = asctime(localtime(&t));
write(fd, buf, strlen(buf));
close(fd);
sleep(2);
}
}
运行程序后,使用 watch -n 1 cat /tmp/daemon.log 持续监测写文件情况
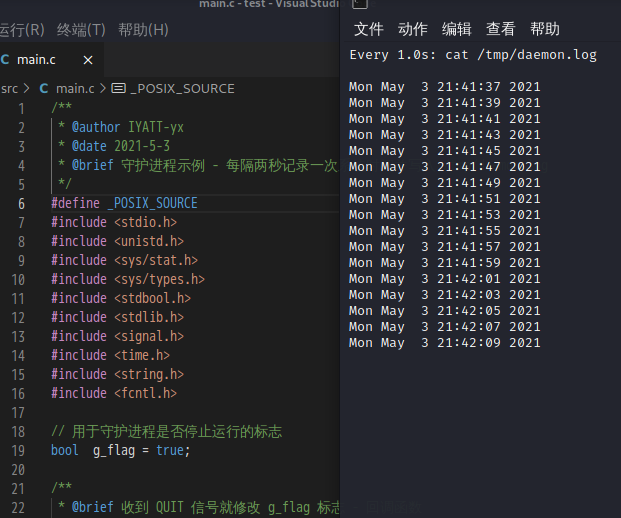
使用 ps 和 grep 查找进程 ID,并使用 kill 发送 QUIT 信号结束进程。

也可以使用库函数 daemon 创建守护进程,只需要将上面代码中自己写的 createDaemon 替换为库函数 daemon。
/**
* @author IYATT-yx
* @date 2021-5-3
* @brief 守护进程示例 - 使用 daemon 函数
*/
#define _GNU_SOURCE
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <stdbool.h>
#include <stdlib.h>
#include <signal.h>
#include <time.h>
#include <string.h>
#include <fcntl.h>
// 用于守护进程是否停止运行的标志
bool g_flag = true;
/**
* @brief 收到 QUIT 信号就修改 g_flag 标志 - 回调函数
* @param sig 传入捕获到的信号值
*/
void changeFlag(int sig)
{
(void)sig;
g_flag = false;
}
int main(void)
{
if (daemon(0, 0) == -1)
{
perror("daemon error\n");
exit(EXIT_FAILURE);
}
struct sigaction act;
act.sa_handler = changeFlag;
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
if (sigaction(SIGQUIT, &act, NULL) == -1)
{
exit(EXIT_FAILURE);
}
while (g_flag)
{
int fd = open("/tmp/daemon.log", O_WRONLY | O_CREAT | O_APPEND, 0664);
time_t t = time(NULL);
char *buf = asctime(localtime(&t));
write(fd, buf, strlen(buf));
close(fd);
sleep(2);
}
}
可能也有注意到上面两个源码开头分别定义的 _POSIX_SOURCE 和 _GNU_SOURCE ,含义可以自己查看,或者我这里写本博文时下载的离线网页文件。