最近更新于 2024-05-05 14:19
数据存放
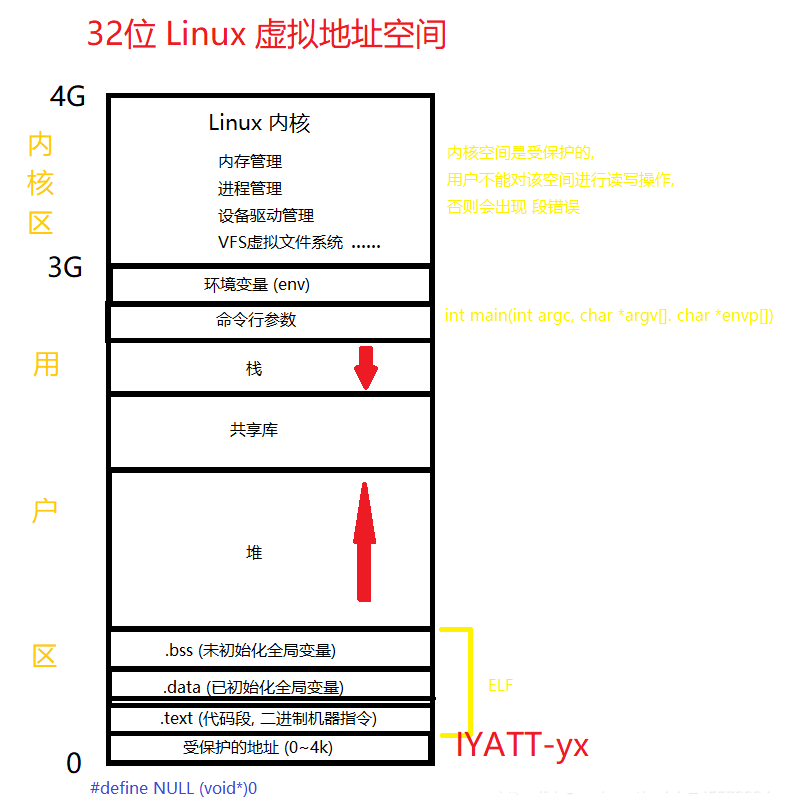
64位分布要复杂些,寻址空间并不是64位,使用其中一部分,其它作为扩展,分布看情况而定。理解大体分布就看32位的更好。对于内存管理这部分只是谈其中用户区的一部分。
.bss(未初始化的全局变量)
该段用来存放没有初始化和初始化为0(包括值改为0)的全局变量和静态变量。

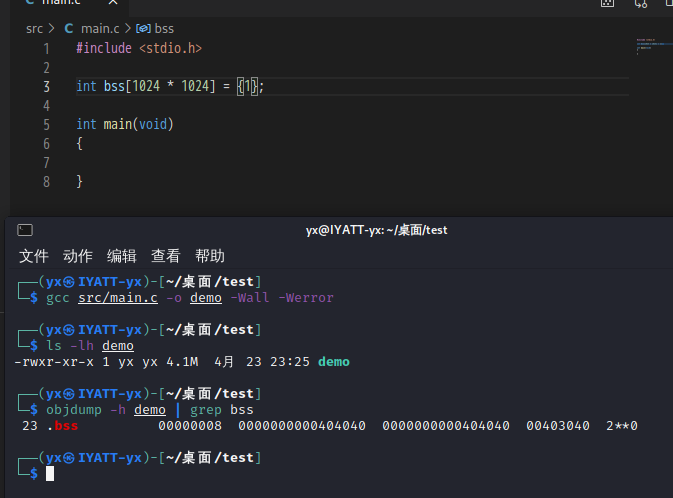
上面代码定义的全局变量大小为 1024 x 1024 x 4 / (1024 x 1024) MB= 4 MB,但是生成的可执行程序文件大小仅 17KB ,也说明 bss 不占用文件空间,只是运行时占用内存空间。
该段数据在运行期间全程存在。
.data (初始化过的全局变量)
存放初始化过的且值不为0的全局变量或者静态变量。
而改为初始为非0值后,文件就变为 4MB多了。说明 data 会占用文件空间,当然运行时也会占用内存空间。
该段数据在运行期间全程存在。
.rodata (常量数据)
这个段在上面地址空间分布图中没有标出,一般它在程序运行时加载,和 text 合并到同一个段。该段主要存放只读数据,比如字符串常量以及const修饰的全局变量。
· 常量不一定就存放在 rodata 里,有的直接和指令编码在一起,存放在 text。
· 对于字符串常量,编译器会自动去除重复的字符串,保证一个字符串在一个二进制文件中只存在一份复制。
· rodata 在多个进程间是共享的,这样可以提高运行空间利用率。
· 在有的嵌入式系统中,rodata 放在 ROM (或者 NOR Flash)里,运行时直接读取,不需要加载到内存中。在嵌入式Linux系统中,也可以通过一种叫做 XIP (就地执行)的技术,直接读取,而无需加载到内存中。
· 常量是不能被修改的,修改常量在Linux下会出现段错误。
由此可见,把运行过程中不会改变的数据设为 rodata 是有好处的。在多个进程之间共享,可以大大提高空间利用率,甚至不占用内存空间。同时由于 rodata 在只读的内存也页面 (page)中是受保护的,任何试图对它的修改都会被即时发现,这可以提高程序的稳定性。
.text (代码)
该段用于存放代码(如函数)和部分整数常量,它与 rodata 段很相似,主要不同就是这个段是可以执行的。
stack (栈)
栈用于存放临时变量和函数参数。栈作为一种基本数据结构,可以用来实现函数的调用,要实现递归操作,不用栈不是不可能,只是找不出比它更好的方式。尽管大多数编译器在优化时,会把常用的参数或者全局变量放入寄存器中。但用栈来管理函数调用时的临时变量(局部变量和参数)是通用做法,前者只是辅助手段,且只在当前函数中使用,一旦调用下一层函数,这些值任然要存入栈才行。
通常情况下,栈向下增长,每向栈中 PUSH 一个元素,栈顶就向低地址扩展,每从栈中 POP 一个元素,栈顶就向高地址回退。要注意的是,存放在栈中的数据只在当前函数和下一层函数中有效,一旦函数返回,这些数据也被自动释放了,继续访问这些变量是UB(未定义的行为,后同),我们应该避开这样使用。
heap (堆)
堆是最灵活的一种内存,它的生命周期完全由使用者控制。ISO C提供以下几个函数:
· malloc/calloc 用来分配一块指定大小的内存。
· realloc 用来调整/重新分配一块存在的内存。
· free 用来释放内存。
malloc和free要配对使用。内存分配之后不释放称为内存泄漏(Memory Leak),内存泄漏多了会出现 Out of memory 的错误,再分配内存就会失败。当然释放时也只能释放自己分配的内存,释放无效的内存或者重复free都是不行的,会造成程序崩溃(crash)。分配多少内存就用多少内存,不管是读还是写,都只能在自己分配的大小范围内,读多了会读到垃圾值,写多了会造成随机破坏,这种情况我们称为缓冲区溢出(Buffer Overflow),这是非常严重的,大部分安全问题都是由缓冲区溢出引起的。
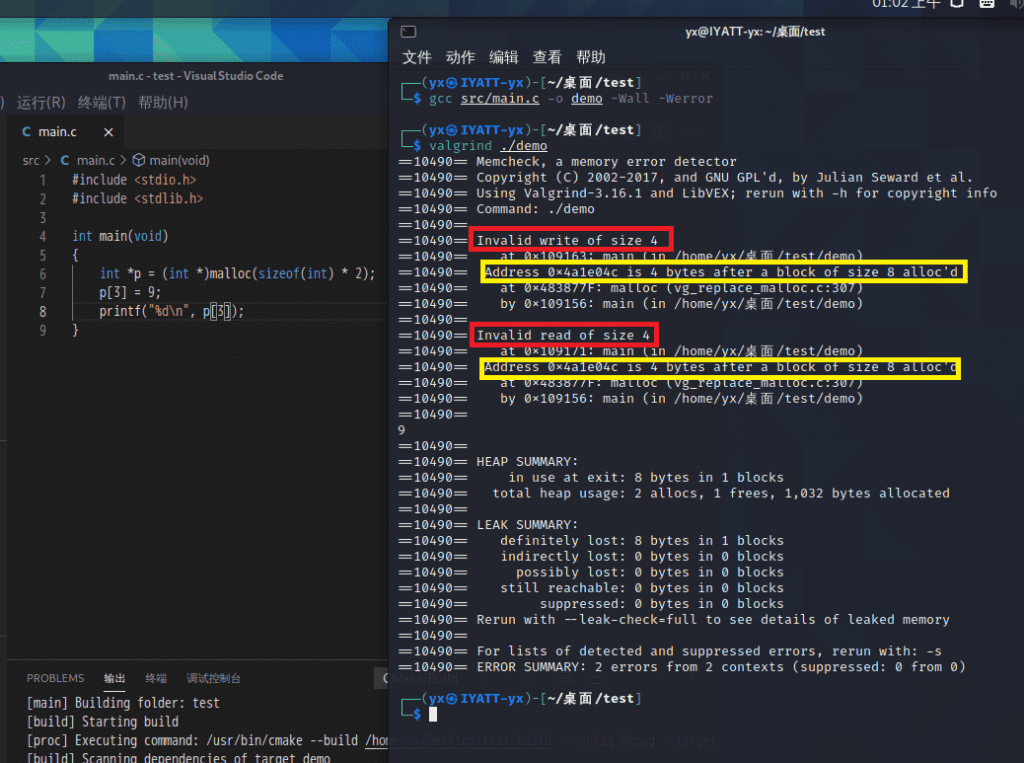
上面代码中申请了两个int大小的内存(视为数组),但是我向它的第4个位置写入了数据,并且也正常读取了,全然看似正常运行,但是说不定下次哪个时候就是一个运行错误(潜在的bug)。
在实际开发中程序十分复杂,手动检查有没有内存泄漏或者缓冲区溢出是很困难的,不过也有工具可以使用,比如 valgrind,可以自己安装。
sudo apt install valgrind
通过valgrind运行可以看到(上图),两个红框分别标出的无效写入和无效读取的大小,黄框是无效操作的地址,我申请的是2个大小(黄框中可以看到申请的是8字节)(合法可操作的是 p[0] 和 p[1]),那么p[2]位置为第一个越界,它的地址是p[1]的结尾,为 0 bytes, 现在我操作的是 p[3] ,我的64位机器上int是4字节,所以再超出一位,错误操作地址是 4 bytes。
_________________________________________________________________________
通过命令查看程序运行时的空间分配情况
cat /proc/self/maps

每个区间都有4个属性:
r 可以读取
w 可以修改
x 可以执行
p/s 是否为共享内存
对于有文件名的内存空间,属性为 r-p 标识存放的是 rodata,属性为rw-p 标识存放的是bss 和 data,属性为 r-xp 标识存放的是 text 数据;对于没有文件名的内存区间,标识用mmap映射的匿名空间;文件名为 [stack] 的内存区间标识的是 栈 ;文件名为 [heap] 的内存区间表示的是堆。
内存分配
内存分配方式有3种:
(1)从静态储存区域分配。内存在程序编译时就已经分配好,这块内存在程序的整个运行期间都存在,如全局变量,静态变量。
(2)在栈上创建。在执行函数时,函数内局部变量的储存单元都可以在栈上创建,函数执行结束时这些储存单元自动被释放。栈内存分配运算使用内置于处理器的指令集,效率很高,但分配的内存容量有限。
(3)在堆上分配,也称动态内存分配。程序在运行时申请所需要的内存,程序员可以自己决定在什么时候释放内存。动态内存的生存期由程序员决定,使用非常灵活,但问题也最多。
野指针
野指针不是 NULL 指针,是指向“垃圾内存”的指针,野指针是很危险的。
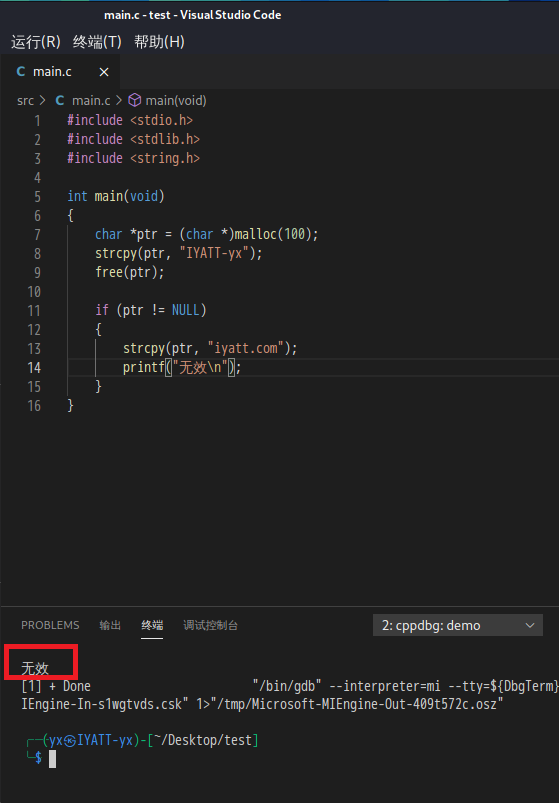
如果程序比较长,我们有时候记不住有没有释放内存,通常使用 ”if (ptr != NULL)“ 进行防错处理,但是遗憾的是,此时if语句不起作用,因为即便 ptr 不是 NULL指针,它也不指向合法的内存块。下面代码种就涉及到操作释放了的内存,尽管编译和运行都没有出错,但是却又是一个潜在的bug,不知道什么时候爆发。
野指针的成因主要有两种:
(1)指针变量没有被初始化。任何指针变量在刚创建的时候都不会自动被初始化为 NULL指针,它的默认值是随机的。所以,指针变量在创建的同时应该被初始化,要么将指针初始化为 NULL,要么分配内存并初始化给它。
(2)指针被释放后,没有设置为 NULL,让人误认为它还是个合法的额指针。free (以及C++种的 delete)只是把指针指向的内存给释放掉,但并没有把指针本身删除掉。即该地址对应的内存变成了“垃圾”,这个指针成了“野指针”。
常见内存错误
发生内存错误是非常麻烦的事。编译器不能自动发现这些错误,通常是在程序运行时才能捕捉到,而这些错误大都没有明显的症状,时隐时现,增加了改错的难度。
(1)内存分配未成功,却使用了它。在使用内存前先检查指针是否为 NULL。如果指针是函数的参数,那么在函数的入口处用 “assert(ptr != NULL)”进行检查;如果是自己申请的内存,应该用“if (ptr != NULL)” 或 “if (ptr == NULL)” 进行防错处理。
(2)内存分配成功,但是尚未初始化就引用它。内存的默认初始值究竟是什么并没有统一的标准,所以无论用何种方式创建数组,别忘了赋初值,即便是赋0值也不要省略。
(3)内存分配成功且已经初始化,但操作越界。上面介绍堆区,举例的代码就是这种情况。
(4)忘记了释放内存,造成内存泄漏。含有这种错误的函数每被调用一次就丢失一块内存。刚开始系统的内存充足,不容易看到错误,总有一次程序会突然死掉,系统出现内存耗尽的提示。动态内存的申请与释放必须配对,申请多少次就应该释放多少次,否则指不定什么时候就出错了。
(5)释放了内存却继续使用它:
① 程序中对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
② 函数的 return 语句写错了,注意不要返回指向 “栈内存” 的指针,因为该内存在函数体结束时被自动销毁了。
③ 释放内存后,没有将指针设置为 NULL,导致产生野指针。
段错误及调试方法
段错误就是访问了错误的内存段,一般是没有权限,或者根本就不存在对应的物理地址,尤其是常见的访问 0 地址。
一般来说,段错误就是指访问超出了系统所给这个应用程序的内存空间,通常这个值是由 gdtr 来保存的,它是一个48位的寄存器,其中32位用于保存由它指向的 gdt 表;后13位用于保存相应的 gdt 下标;最后3位包括了程序是否在内存中,以及程序在CPU种的运行级别。指向 gdt 是一个以 64 位为单位的表,在这张表中保存着程序运行的代码段、数据段的起始地址,以及与此相对应的段限和页面交换还有程序的运行级别,以及内存粒度等信息。一旦一个程序发生了越界访问,CPU就会产生相应的异常保护,于是 segmentation fault 就出现了。
我们在用 C/C++ 编写程序的时候,内存管理的绝大部分工作都属需要我们来做的。实际上内存管理是一个标胶繁琐的工作,无论你多高明,经验多丰富,难免会在此处犯些小错误,而通常这些错误又那么浅显而易于消除。但是手动寻找bug往往是低效且让人厌恶的,下面就谈谈如何快速定位”段错误“。
下面就用这段存在段错误的代码来示范:
void segmentation(void)
{
unsigned char *ptr = 0x00;
*ptr = 0x00;
}
int main(void)
{
segmentation();
}
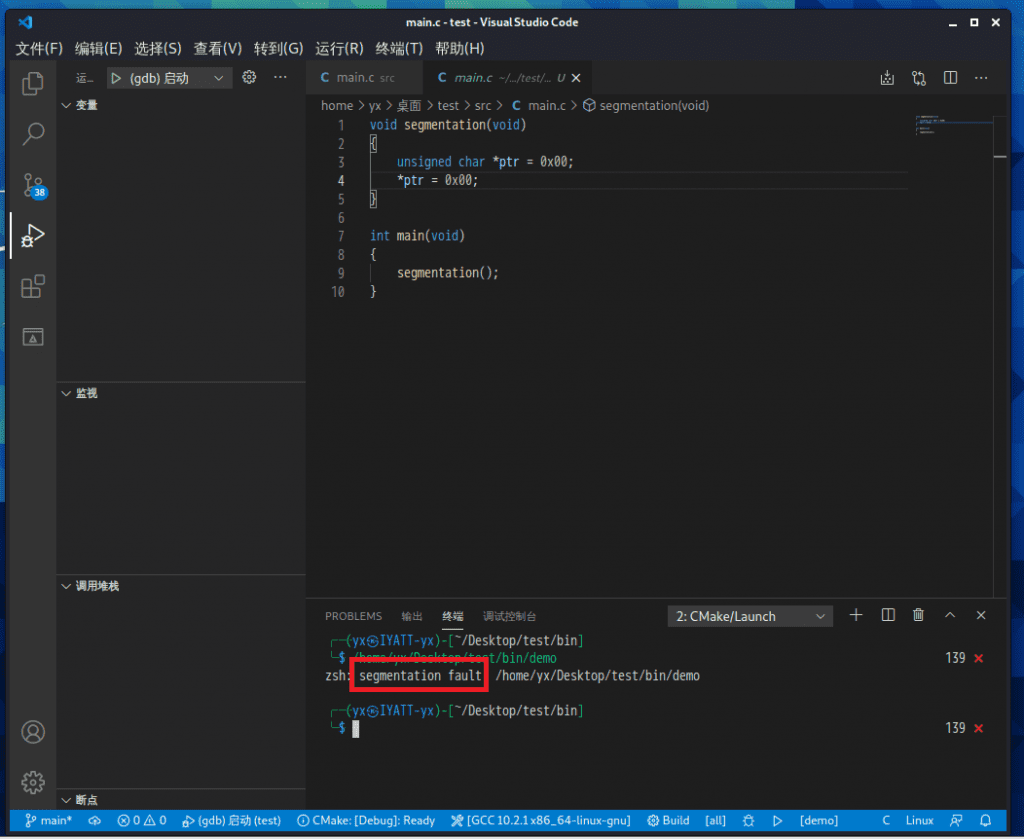
gdb调试
编译的时候加上 -g -rdynamic 参数,然后用 gdb ./[程序文件名] 运行

我一般都不用命令敲 gdb 调试,在 vscode 里添加 C/C++ 插件,编译好后,
按 F5 ,默认选项在第一个 gdb 上,回车
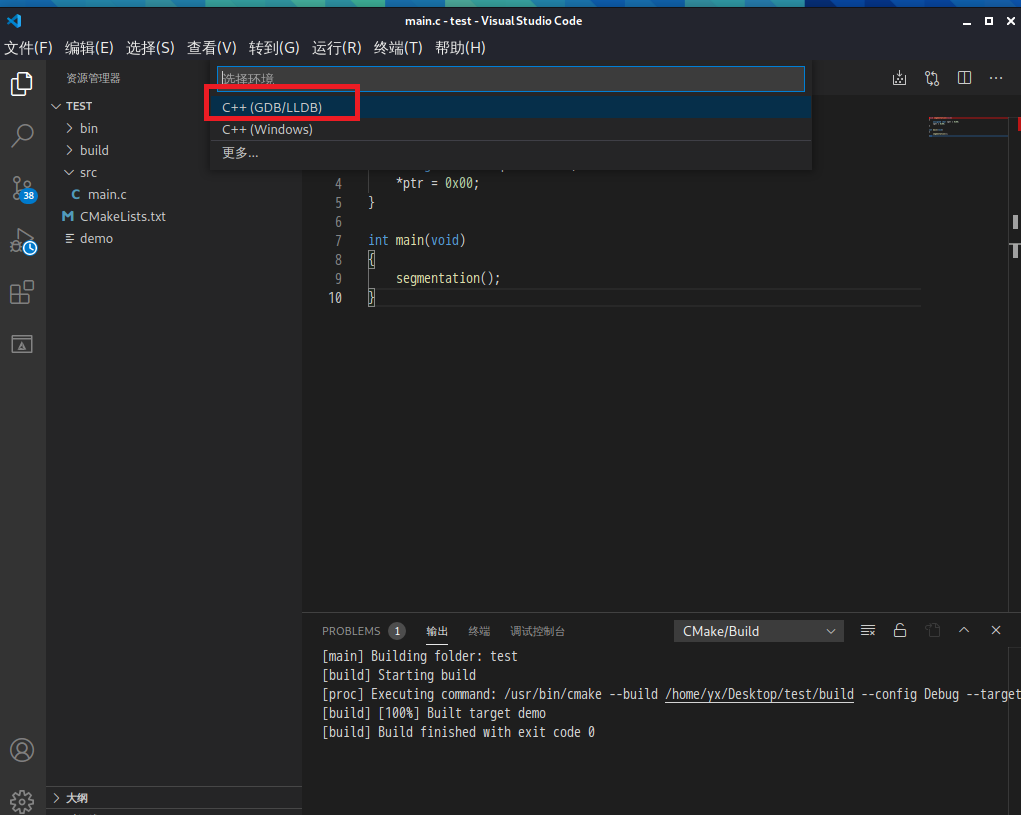
选择默认配置,回车

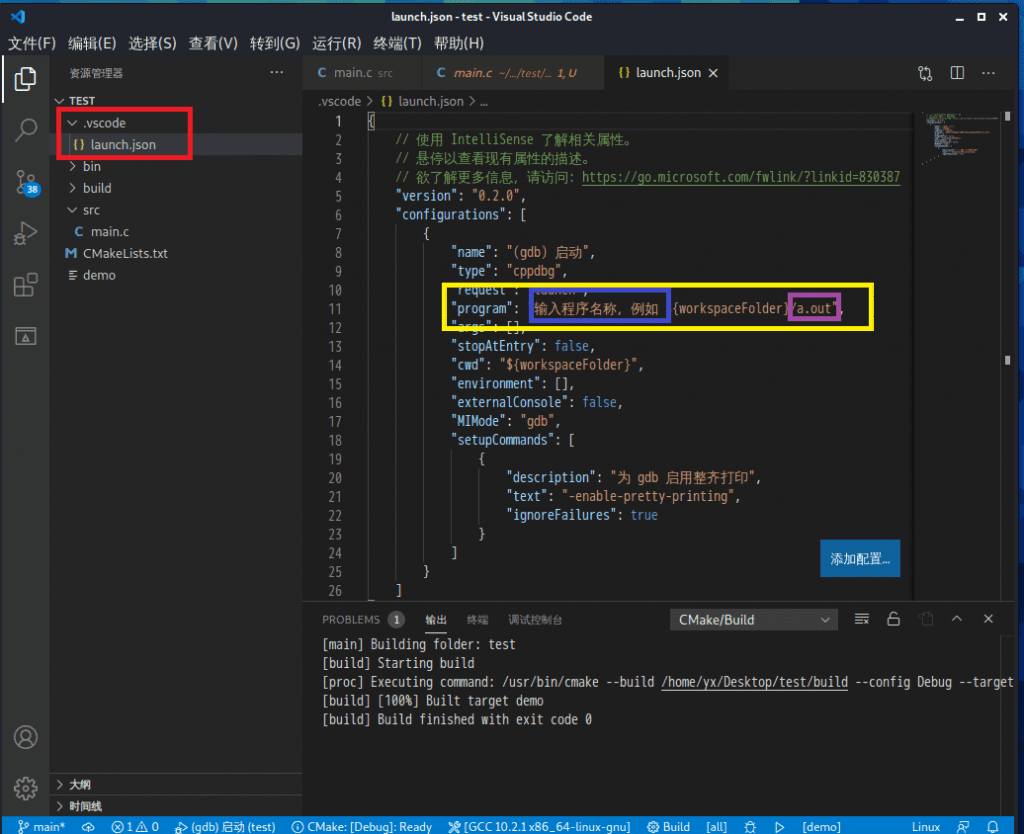
可以看到在项目文件夹下生成了配置文件(红框),然后编辑配置文件,黄框部分用于指定可执行程序文件路径,将蓝色框的中文文字和空格删掉,$符号跟着花括号那段表示路径为当前项目文件夹根,然后紫色框部分改为生成的可执行文件在项目文件夹下的相对路径,然后按 Ctrl + S保存,Ctrl + W关闭当前的编辑框,之后按 F5 就可以调试。
我这里是通过配置的 cmake 进行编译,使用的模板已经在前面工程管理列出来了,这个模板中我设定的是生成可执行文件(文件名为 demo)放入到项目文件夹下的 bin 目录中 (cmake的时候会创建这个目录)。所以我这里改为:
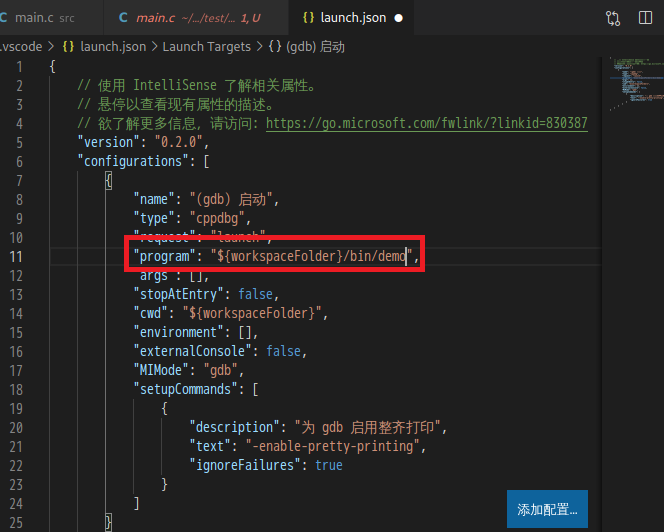
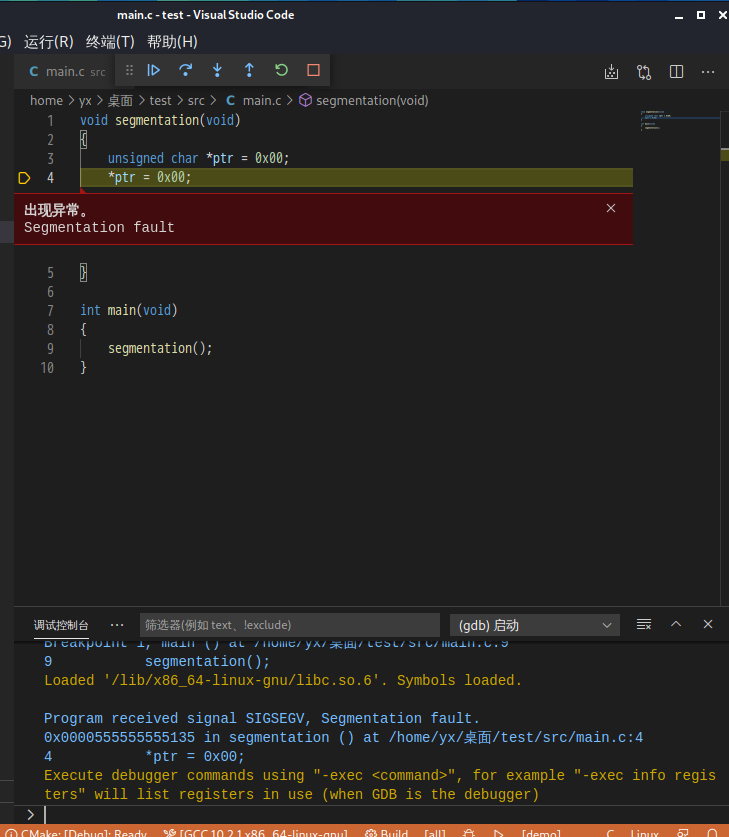
然后直接按 F5 调试运行(注意先编译,才能调试,不然程序文件都不存在,你运行调试啥),直接指出错误位置,更为易用:
分析 core 文件
详情可以使用 man 5 core 查阅
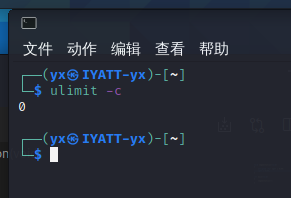
我使用的 Kali Linux 默认禁止了 core 文件的产生,使用 ulimit -c 查看,发现为 0,即没有为 core 设置储存空间。
那么我用命令临时设置 core (只在当前执行修改命令的终端窗口有效),设置 core 大小限制为 512KB
ulimit-c 1000
然后编译程序和执行(编译的时候至少要加上 -g 参数,会将源码文本放入程序文件中,方便调试的时候能够直接给你定位指出代码错误位置)

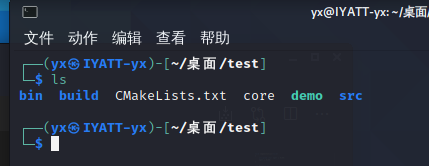
可以看到当前目录下产生了 core 文件
然后分析 core 文件,可以看到也是指出了第四行代码
gdb [程序文件路径(文件名)] core
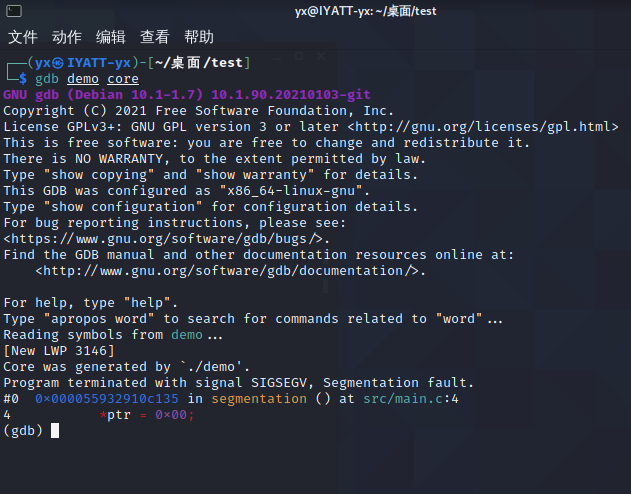
此法适合在运行程序时,没有准备gdb调试,但是意外遇到了错误,可以通过错误时产生的 core 文件进行分析。