最近更新于 2024-05-05 14:19
本文资源文件下载:https://pan.baidu.com/s/1m2ibm5RFV9O9nu6xg5egbg?pwd=j2mq
方式一:OpenCV DNN + YOLOv5 预训练模型
模型文件下载及转换
这里采用的 YOLOv5 版本为 6.1
下载模型文件:https://github.com/ultralytics/yolov5/releases/tag/v6.1
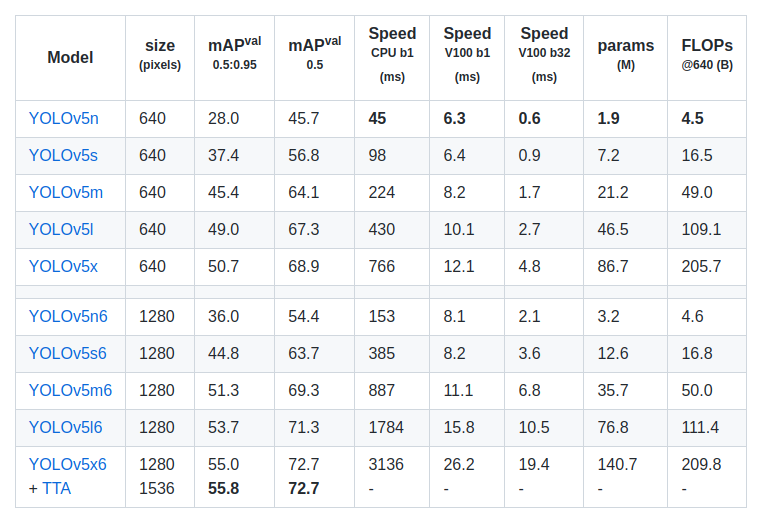
获取 YOLOv5 源码
git clone https://github.com/ultralytics/yolov5.git --depth=1 --branch=v6.1
安装 YOLOv5 依赖环境
pip3 install -r yolov5/requirements.txt
提供的模型文件格式为 YOLOv5 格式,OpenCV DNN 模块无法使用,这里需要转换为 ONNX 格式,我把下载的 .pt 模型文件放到了 models 文件夹下
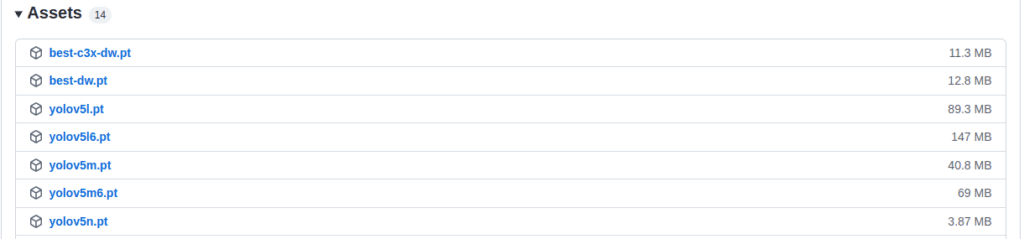
python3 yolov5/export.py --weights models/yolov5n.pt --include onnx python3 yolov5/export.py --weights models/yolov5s.pt --include onnx python3 yolov5/export.py --weights models/yolov5m.pt --include onnx python3 yolov5/export.py --weights models/yolov5l.pt --include onnx python3 yolov5/export.py --weights models/yolov5x.pt --include onnx
转换完成得到 ONNX 文件,生成的文件是在当前运行路径下的,然后将这些文件拷贝到 models 目录下
这些预训练模型训练使用的数据集为 coco,其中包括了 80 中物体类型,具体可查看 coco.names。
目标检测程序运行
测试环境使用的是 Docker 镜像:blog.iyatt.com-ubuntu_20.04-cuda_11.3.0-cuDNN_8.2.1-opencv_contrib_4.5.5-gnu_9.4.0-python_3.10.4.tar
在 jupyer 中运行目标检测.ipynb笔记本,即可通过摄像头预览并识别物体
在使用 n 模型时,CPU 计算帧率不超过 4 帧(Inter i5 8265U)
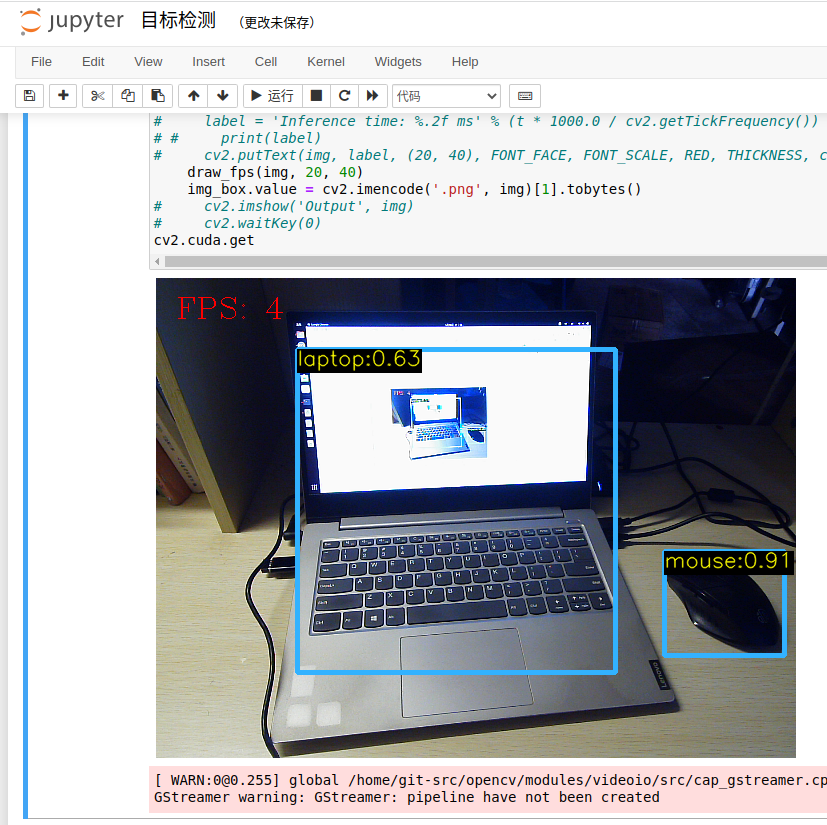

n 模型使用 GPU 加速时,虽然我轻薄本的 GPU 很垃圾,但是比起纯 CPU,帧率还是可以翻一倍(NVIDIA GeForce MX230)

上面测试使用的都是 n 模型(速度最快,准确度最差),然后我再尝试一下 x 模型(速度最慢,准确度最高),帧率就很惨了,但是确实准确度高了,前一个都没有把那些书识别出来,这个却可以识别出来。
但是 GPU 基本上满载了,风扇狂转。

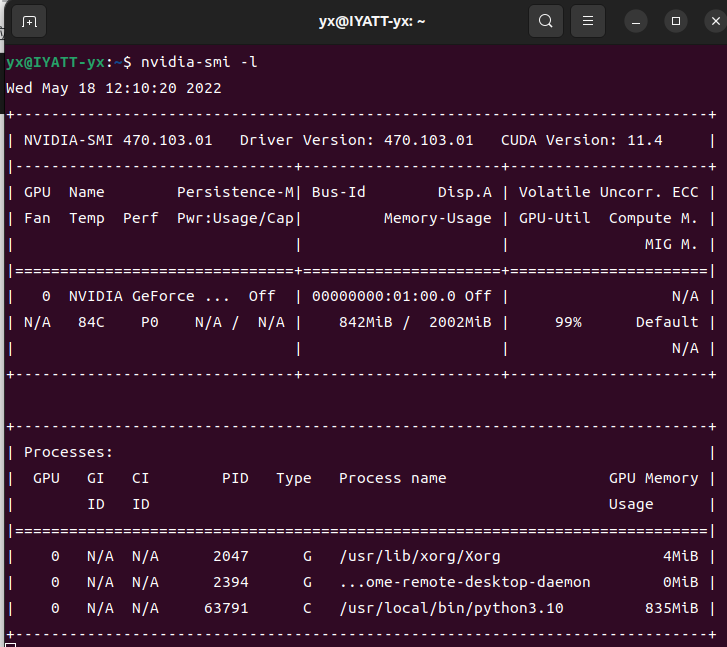
对于算力不是很强的计算机设备,一般建议使用 s 模型,相比于 n 模型,计算量的提升相对于准确度的提升还是比较值得的。如果是像树梅派、Jetson Nano这些小型计算机板的话,那就建议 n 模型了,算力毕竟太有限,我在树莓派4B 4G上试了一下,帧率为 1。
方式二:YOLOv5
这里是后期补的,因为我发现直接使用 YOLOv5 比转换模型后使用 OpenCV 速度快不少,当然配置环境就要再多安装一个 PyTorch。
我测试使用的 PyTorch 版本为 1.11.0,YOLOv5 版本 6.1,很可能会遇到报错 AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’,解决方案:https://blog.iyatt.com/?p=6422
代码文件为 目标检测yolov5.ipynb,下面测试都是使用的 n 模型
CPU(Inter i5 8265U)

GPU (GeForce MX230)

Jetson Nano
