最近更新于 2024-05-05 14:19
发布于:blog.iyatt.com
本文资源文件下载:https://pan.baidu.com/s/1pjQiroUfqpxJp4JEdcaaLg?pwd=oqcu
测试环境(基础):
Ubuntu 20.04 x86_64 Python 3.9.10 jupyter 1.0.0 opencv-python 4.5.5.64 torch 1.11.0
车牌识别的第一步就是需要车牌定位,在图像中找到车牌的位置。刚开始我尝试过纯视觉处理,但是环境变化对效果影响很大,准确度太低,没法实际应用。后面了解到 opencv 提供了训练好的级联分类器模型,我尝试了一下,效果不太好,才注意到这个模型是针对俄罗斯车牌的。所以最后决定还是采用人工神经网络,这里我使用的是 YOLOv5。
YOLOv5 环境配置
sudo apt update sudo apt install -y build-essential cmake pkg-config git cd ~ git clone https://github.com/ultralytics/yolov5.git --branch=v6.1 --depth=1 # YOLOv5 6.1 cd yolov5 pip3 install -r requirements.txt
数据集
CCPD:https://github.com/detectRecog/CCPD
CCPD(中国城市停车数据集,ECCV)和PDRC(车牌检测与识别挑战)。这是一个用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline。
该数据集在合肥市的停车场采集得来的,采集时间早上7:30到晚上10:00.涉及多种复杂环境,图片大小为 720x1160x3。一共包含9项。每项占比如下:
CCPD 2019
| CCPD- | 数量/千 | 描述 |
| base | 200 | 正常车牌 |
| fn | 20 | 拍摄距离相当近或者相当原 |
| db | 20 | 光线暗或者比较亮 |
| rotate | 10 | 水平倾斜 20~25 度,垂直倾斜 -10~10 度 |
| tilt | 10 | 水平倾斜 15~45 度,垂直倾斜 15~45 度 |
| weather | 10 | 雨天,雪天或雾天 |
| blur | 5 | 由于相机抖动造成的模糊 |
| challenge | 10 | 比较有挑战性的车牌 |
| np | 5 | 没有车牌的 |
数据集中每张图片的命名是标注,比如:
01-1_3-263&456_407&514-407&510_268&514_263&460_402&456-0_0_10_23_32_28_33-166-2.jpg
- 01 我也没查明白这是个啥
- 1_3 水平倾斜角 1 度,垂直倾斜角 3 度
- 263&456_407&514 边界框坐标:左上(263,456),右下(407,514)
- 407&510_268&514_263&460_402&456 对应四个角点右下、左下、左上、右上
- 0_0_10_23_32_28_33 车牌号,映射关系为:
# 第一位 provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"] ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']
166 亮度
2 模糊度
—————————————————————————————————————————————
我这里使用的数据集是其中的 ccpd_base(都是蓝牌,CCPD 2020 中是绿牌), 190k 张用作训练集,剩余的约 10k 张用作验证集测试调整参数。已打包为 ccpd_base.tar.bz2
CCPD 数据集本身的标注和 YOLOv5 的不同,坐标和长度都需要归一化
类别标签 目标中心x值/图像宽度 目标中心y值/图像高度 目标宽度/图像宽度 目标高度/图像高度
我写了一个脚本,可以运行 YOLO 标签生成.py 得到 YOLOv5 要求的标签
配置文件
创建文件 data.yaml,写入数据集路径(相对 train.py 的路径)和目标标签类别
train: ../ccpd_base/images/train val: ../ccpd_base/images/val nc: 1 # 要识别的目标种类数 names: ['license-plate'] # 要识别的目标名
训练
- –batch 指定一次处理的数据量,根据显存大小而定。可以自行尝试,如果显存不够会报错的(AttributeError: ‘NoneType’ object has no attribute ‘_free_weak_ref’)。
- –epoch 训练多少次
- –data 指定配置文件路径
- –weights 指定使用的预训练权重文件(可以自动在线下载最新的)
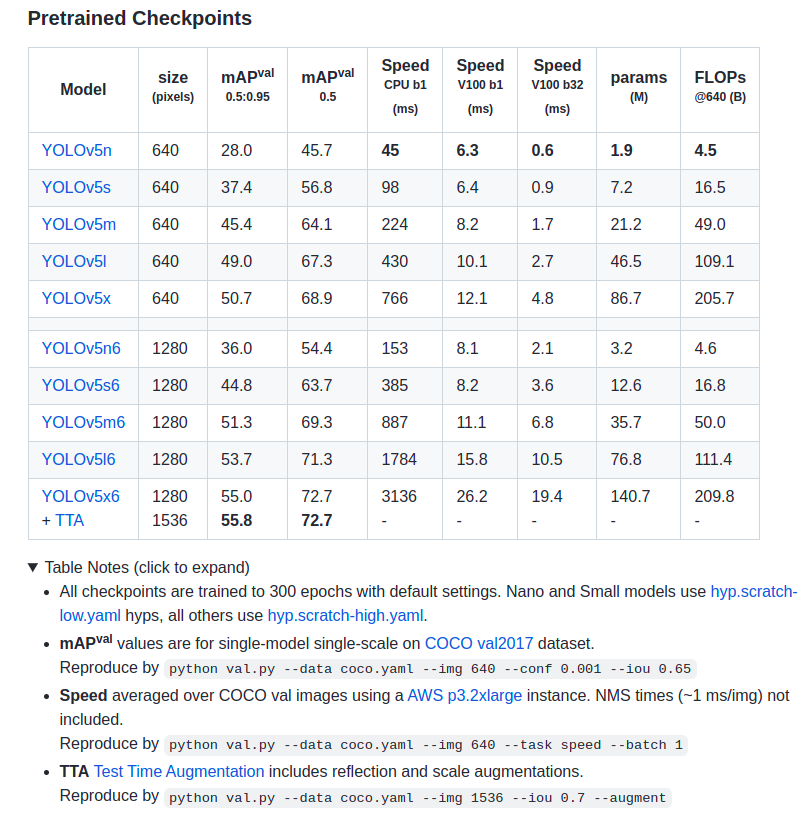
n、s、m、l、x 顺序精确度越来越高,但是计算量越来越大,则速度越来越慢,需要根据自己的应用场景进行选择。我这里是要在小型计算机板上部署,因此计算量是首要考虑的,所以选择计算量最小的 n 模(YOLOv5n.pt)。
python3 yolov5/train.py --img 640 --batch 8 --epoch 3 --data data.yaml --weights yolov5n.pt
190k 张图片,训练还是很耗时的,在我笔记本上跑了一天时间。
训练生成的文件在 yolov5/runs/train 目录下
下面是训练集中的部分图标注

完成训练后,会用验证集中的图片进行测试并调整参数

车牌定位
前面训练得到的权重文件在 weights 目录中,一个是 best.pt, 另外一个是 last.pt,应该是指效果最好的的模型和最新的模型,我都统一用 best.pt。
通过 YOLOv5 提供的 detect.py 脚本就可以使用模型进行预测
# --weights 指定权重文件路径 # --source 指定图片或者视频路径 # 结果可以在 yolov5/runs/detect 查看 python3 yolov5/detect.py --weights yolov5/runs/train/exp/weights/best.pt --source 'ccpd_base/images/val/0445977011495-90_90-100&339_515&479-510&463_122&469_124&350_512&344-0_0_4_15_32_29_32-50-19.jpg'

detect.py 可以预测图像上的车牌并标注出来,并保存为图片。但是这不满足车牌定位的要求,车牌定位是要提取仅含车牌的图像数据,所以还是得自己写代码。运行 车牌定位.ipynb 笔记本可以看效果。


