最近更新于 2024-05-05 14:19
在 Linux 下搞 C/C++ 编程开发,最为常用的编译工具为 GNU 编译器(gcc/g++)。对于很多初学者而言,写了代码可能就敲命令编译,这很正常。但是当进行一个较大的工程的时候,代码文件成百上千,这个时候都还是敲 gcc 命令编译?调试的时候,有时候只改了一个代码文件,也要所有代码都重新编译一遍?这个时候直接用 gcc 命令就会显得力不从心了。
那么这里就引入 make 的介绍。make 工具本身类似于一套脚本执行器,依托于 Makefile 文件执行。在 Makefile 中编写一定的规则,make 根据 Makefile 中的要求去调用相关的工具执行工程的构建。并且不仅限于简单的编译,在执行编译前会检查文件时间戳,再一次编译时发现有源码文件的时间新于目标文件才会重新编译,否则沿用旧的,对于工程的构建也节省了一定的时间。
Windows 下 Visual Studio(VS)也包含了一个和 make 类似的工具,叫做 nmake,Makefile 文件的编写规则和 make 也有大半是相似的。
编译工具链安装
针对 Debian 系 Linux,即使用 apt 安装包管理工具的。
sudo apt update sudo apt install -y build-essential
GNU 编译器的一些常用选项介绍
选项官方文档:https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
-Wall 选项
- -Wchar-subscripts 这个选项针对数组的下标值,如果下标值是 char 则给出警告。因为在一些平台上,char 类型的变量可能定义为 signed char(有符号整数),所以用 char 类型的变量做下标的时候,如果下标值为负数可能会造成内存溢出。
- -Wcomment 这个选项针对代码中的注释,在出现不合适的注释格式的时候会出现警告。例如在 “/* … */” 中间出现 “/*”,或者在 “// …” 注释的末尾出现“\” 的时候,给出警告。
- -Wformat 这个选项针对输入输出的格式,检查 printf 和 scanf 等格式化输入输出函数的格式字符串与参数类型的匹配情况,如果不匹配就会给出警告。
- -Wimplicit 这个选项针对参数的声明,集合了 -Wimplicit-int 和 -Wimplicit-function-declaration 两个选项。第一个选项在声明函数时,如果没有指定返回值就给出警告; 第二个参数如果在声明前调用函数就给给出警告。
- -Wmissing-braces 这个选项针对结构类型或者数组初始化时的不合适格式,如 int array[2][2] = {0, 0, 1, 1}; 由于初始化的表达式没有充分用 {} 括起来,编译器会给出警告,正确应该采用下面的定义方法:int array[2][2] = {{0, 0}, {1, 1}};
- -Wparentheses 这个选项针对多种优先级的操作符在一起或者代码结构难以看明白的操作,如果没有将操作进行明确地分离,编译器会给出警告。例如 if (a && b || c)中的三个变量 a、b 和 c 的操作顺序应该用括号分离。
- -Wsequence-point 这个选项针对顺序点,如果在代码中使用了有可能造成顺序点变化的语句,编译器会给出警告。例如,代码 i=i++ 在不同的编译器上得到的结果会不同(标准中没有规定顺序,实际顺序由编译器决定。标准中未规定的行为一般称为未定义行为 – undefined behavior,简称 UB),如果使用了这样的代码就会给出警告。
- -Wswitch 这个选项针对 switch 语句,如果一个 switch 语句中没有添加 default 条件,编译器会给出警告。
- -Wunused 这个选项针对代码中没有用到的变量、函数、值、跳转点等,它是 -Wunused-function、-Wunused-label、-Wunused-variable、-Wunused-value 选项的集合。-Wunused-function 警告代码中没有使用的静态函数,或者只定义却没有实现的静态函数。-Wunused-label 警告代码中定义了却没有使用,或者使用了却没有定义的标签。-Wunused-variable 警告代码中定义了却没有使用的局部变量。-Wunused-value 警告代码中计算表达式的结果没有使用。
- -Wunused-parameter 这个选项针对函数参数,如果一个函数的参数在函数实现中没有使用到,编译器就会给出警告。
- -Wuninitialized 这个选项针对没有初始化变量的使用,如果一个局部变量在使用之前没有初始化,编译器就会给出警告。
非 -Wall 选项
- -Wflot-equal 这个选项针对浮点值相等的判定,由于浮点值的确切值难以得知,所以如果浮点值出现在相等判定的表达式中,编译器会给出警告。浮点值的相等判定可以用浮点值的差与某个小值比较判定,比如我认为两个浮点数的差的绝对值小于 0.000001 就是相等。
- -Wshadow 这个选项用于局部变量作用域内的同名变量,如果局部变量的作用域范围内有其它同名变量时,局部变量会遮蔽全局变量,此时编译器给出警告。
- -Wbad-function-cast 这个选项针对函数的返回值,当函数的返回值赋给不匹配的类型时,编译器会给出警告。
- -Wsign-compare 这个选项针对有符号数和无符号数的比较,由于无符号数的优先级比有符号数的优先级高,二者进行比较运算的时候,会先将有符号数转为无符号数。在负的有符号数和无符号数进行比较的时候,容易出现错误,编译器会给出警告。
- -Waggregate-return 这个选项针对结构类型的函数返回值,如果函数的返回值为结构、联合等类型时,编译器会给出警告。
- -Wmultichar 这个选项针对字符类变量的错误赋值,当使用 char c = ‘test’ 这样的代码时,编译器会给出警告。
- -Wunreachable-code 这个选项针对冗余代码,如果代码中有不能到达的代码时,编译器会给出警告。
- -Werror 将警告当作错误处理。原本警告的内容直接报错并停止编译。
语言标准
- -ansi 与 ANSI C 兼容
- -pedantic 允许发出 ANSI/ISO C 标准所列出的所有警告。
- -pedantic-errors 允许发出 ANSI/ISO C 标准所列出的所有错误
- -std 指定语言标准,对 C 语言有如 c89、c90、c99、c11、c17,对 C++ 有如 c++98、c++11、c++14、c++17,使用格式如 gcc -std=c17 和 g++ -std=c++17。当然 C++ 20 其实已经有确定版了,只是我 Ubuntu 20.04 LTS 系统目前 apt 能安装的 GNU 编译器的最高版本与 GNU 最新版本还是差一些,没支持,如果用源码编译安装最新版的 GNU 编译器肯定是支持的(编译安装 GNU 编译器参考: https://blog.iyatt.com/?p=2057),另外目前 C++23 和 C23 都在开发中了,中译版标准文档参考:https://zh.cppreference.com/。
调试
- -g 在编译生成的二进制文件中添加调试信息,比如会将代码文本放进去,gdb 调试的时候也能设置断点。
- -fsyntax-only 仅进行编译检查但不实际编译生成二进制文件
- sanitize 系列参数,参考:https://blog.iyatt.com/?p=3384
编译优化
- -O0 不做任何优化,默认状态
- -O1 程序做部分编译优化,对于大函数,优化编译占用稍微多的时间和相当大的内存。使用本项优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
- -O2 执行几乎所有的不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环打开以及函数内联。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。
- -O3 在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
- -Os 相当于-O2.5。是使用了所有-O2的优化选项,但又不缩减代码尺寸的方法。
编译链接
- -I 后面跟上头文件所在的路径。当编译的程序引用某个头文件,而该头文件不在系统默认搜索路径也不在源码文件同一路径下时需要手动指定,格式如 -I/usr/include 或者 -I /usr/include。
- -L 后面跟上需要链接的库路径。当程序中使用的库不在系统默认的搜索路径或则源码同一路径下,需要手动指定路径,格式如 -L/usr/lib 或者 -L /usr/lib。
- -l 后面指定库名。如果库文件名为 libtest.so,那么使用 -ltest 链接动态库。链接第三方库以及部分标准库时需要指定库名,比如 C 中有时候使用到数学库,编译就要指定 -lm。
一个多源码文件工程示例
工程结构
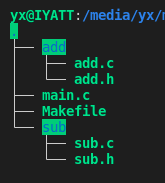
源码
/** * @file add.h * @brief 整数加法计算 */ #ifndef ADD_H #define ADD_H int add(int num1, int num2); #endif
/**
* @file add.c
* @brief 整数加法计算
*/
#include "add.h"
int add(int num1, int num2)
{
return num1 + num2;
}
/** * @file sub.h * @brief 整数减法计算 */ #ifndef SUB_H #define SUB_H int sub(int num1, int num2); #endif
/**
* @file sub.c
* @brief 整数减法计算
*/
#include "sub.h"
int sub(int num1, int num2)
{
return num1 - num2;
}
/**
* @file main.c
* @brief 主程序
*/
#include "add.h"
#include "sub.h"
#include <stdio.h>
int main()
{
int num1 = 9;
int num2 = 1;
printf("%d + %d = %d\n", num1, num2, add(num1, num2));
printf("%d - %d = %d\n", num1, num2, sub(num1, num2));
}
Makefile
# 左边为要生成的目标,右边为依赖文件 # 生成 demo 的规则,依赖于 .o 文件,但是开始的时候不存在,那么就会先执行后面的,编译生成 .o 文件之后再来链接 demo: add/add.o sub/sub.o main.o gcc -o demo add/add.o sub/sub.o main.o # 生成 add.o 的规则 add.o: add/add.c add.add.h gcc -c -o add/add.o add/add.c # 生成 sub.o 的规则 sub.o: sub/sub.c sub/sub.h gcc -c -o sub/sub.o sub/sub.c # 生成 main.o 的规则 main.o: main.c gcc -c -o main.o main.c -Iadd -Isub # 清理的规则 clean: rm -rf add/add.o sub/sub.o main.o demo
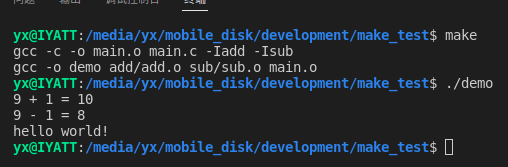
执行编译,生成可执行程序 demo
make

make 执行前会检查文件修改时间,假如这里修改一下 main.c 文件,再执行编译
会发现没有重新再编译 add.c 和 sub.c,只是把修改过的 main.c 重新编译了
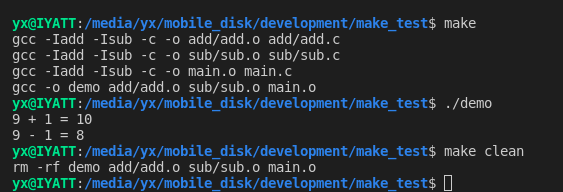
执行清理规则
make clean

make 中的变量
(一)自定义变量
创建一个变量 CFLAGS,赋值 -Iadd -Isub
CFLAGS = -Iadd -Isub
调用变量 CFLAGS
$(CFLAGS)
那么这里将上面的 Makefile 改一下,变成下面的
# 编译器 C = gcc # 编译参数 CFLAGS = -Iadd -Isub # 目标文件 OBJS = add/add.o sub/sub.o main.o # 最终要生成的二进制文件名 TARGET = demo # 删除命令 RM = rm -rf $(TARGET):$(OBJS) $(C) -o $(TARGET) $(OBJS) # %.o:%.c 模式匹配,比如可以将 add/add.o 替换为 add/add.c,直接去编译 add/add.c 文件 # $@ 和 @< 为自动变量,后面(三)中马上要说 $(OBJS):%.o:%.c $(C) $(CFLAGS) -c -o $@ $< clean: $(RM) $(TARGET) $(OBJS)
(二)预定义变量
常用的一些预定义变量
| 变量名 | 含义 | 默认值 |
| AR | 生成静态库文件的程序名 | ar |
| AS | 汇编编译器的名称 | as |
| CC | C 语言编译器的名称 | cc |
| CPP | C 语言预编译器的名称 | $(CC) -E |
| CXX | C++ 编译器的名称 | g++ |
| RM | 删除文件程序的名称 | rm -f |
| ARFLAGS | 生成静态库库文件程序的选项 | 无默认值 |
| ASFLAGS | 汇编编译器的编译选项 | 无默认值 |
| CFLAGS | C 语言编译器的编译选项 | 无默认值 |
| CPPFLAGS | C 语言与编译的编译选项 | 无默认值 |
| CXXFLAGS | C++ 编译器的编译选项 | 无默认值 |
那么这里在前一个 Makefile 的基础上修改一下,其中 CC 和 RM 使用默认值,不再手动指定。如果手动指定,则优先按手动指定的值。
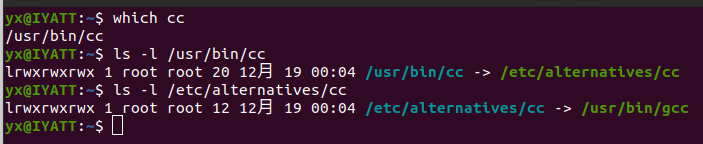
在我 Ubuntu 20.04 LTS 系统上,cc 也是指向 gcc 的
CFLAGS = -Iadd -Isub OBJS = add/add.o sub/sub.o main.o TARGET = demo $(TARGET):$(OBJS) $(CC) -o $(TARGET) $(OBJS) $(OBJS):%.o:%.c $(CC) $(CFLAGS) -c -o $@ $< clean: $(RM) $(TARGET) $(OBJS)
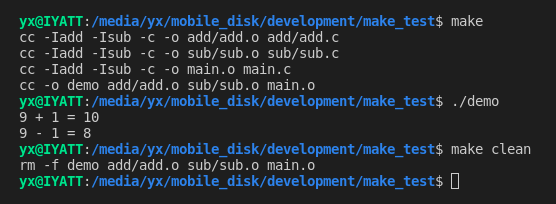
(三)自动变量
常用自动变量
| 变量 | 含义 |
| $* | 表示目标文件的名称,不包含目标文件的扩展名 |
| $+ | 表示所有的依赖文件,这些依赖文件之间以空格分开,按照出现的先后顺序,其中可能包含重复的依赖文件 |
| $< | 表示依赖项中第一个依赖文件的名称 |
| $? | 依赖项中,所有目标文件时间戳晚的依赖文件,依赖文件之间以空格分开 |
| $@ | 目标项中目标文件的名称 |
| $^ | 依赖项中,所有不重复的依赖文件,这些文件之间以空格分开 |
那么这里再在前一个 Makefile 的基础上进行修改
CFLAGS = -Iadd -Isub OBJS = add/add.o sub/sub.o main.o TARGET = demo $(TARGET):$(OBJS) $(CC) -o $@ $^ $(OBJS):%.o:%.c $(CC) $(CFLAGS) -c -o $@ $< clean: $(RM) $(TARGET) $(OBJS)

搜索路径
在较大的项目中,往往存在很多目录,每个文件手动输入路径比较麻烦而且也容易出错,而 make 提供了一个目录搜索功能可以解决这个问题。将路径添加到 VPATH 变量中,路径之间以分号隔开,make 会将指定文件的目录添加到文件上。
那么这里基于前面的 Makefile 再次改进,如下
例如这里就不用再指定 add/add.o,可以写 add.o,只要给出目录 add 添加到 VPATH 中,就会自动添加上这个路径。另外做了一定的修改,编译生成的中间文件和最终的二进制文件都放入 build 目录了。
CFLAGS = -Iadd -Isub VPATH = add:sub OBJSDIR = build OBJS = add.o sub.o main.o TARGET = $(OBJSDIR)/demo RM = rm -rf $(TARGET):$(OBJSDIR) $(OBJS) $(CC) -o $@ $(OBJSDIR)/*.o $(OBJS):%.o:%.c $(CC) $(CFLAGS) -c -o $(OBJSDIR)/$@ $< $(OBJSDIR): mkdir $@ clean: $(RM) $(OBJSDIR)
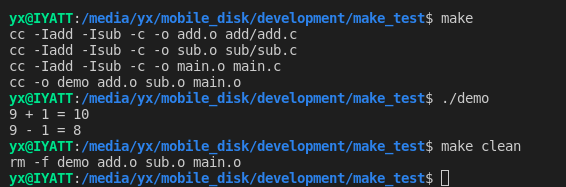
自动推导
Makefile 中关于源文件编译部分的规则可以省略掉,make 会按照默认的规则将 .c 文件编译为 .o 文件,由 make 决定如何使用编译命令以及选项,此默认规则称为 make 的隐含规则。
这里再次在前一个 Makefile 的基础上进行修改,
CFLAGS = -Iadd -Isub VPATH = add:sub OBJS = add.o sub.o main.o TARGET = demo $(TARGET):$(OBJS) $(CC) -o $@ $^ $(CFLAGS) clean: $(RM) $(TARGET) $(OBJS)
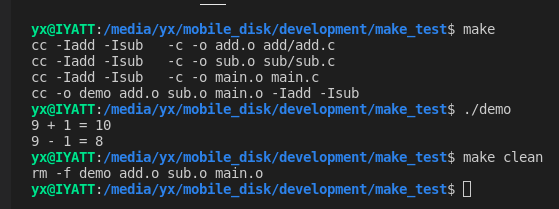
递归 make
在一个工程的开发过程中,往往不只是一个人进行开发,可能一个人负责项目中的一个模块。各个模块的源码在相对独立的目录中,此时由同一个 Makefile 进行组织编译会十分不便,每个模块的源码结构改变都需要修改同一个 Makefile 文件,这在维护时是个问题。
因而 make 支持递归调用,可以通过总 Makefile 递归调用各子目录的 Makefile。这里还是以前面的工程为例,现在一共会有三个 Makefile 文件,分别在 add 和 sub 目录下各增加了一个,项目结构如下

项目根目录下的总控 Makefile
# 需要传递给下层的 Makefile 的变量,可以使用 export
export CFLAGS = -Wall -std=c17
export OBJSDIR = ${shell pwd}/build
TRAGET = $(OBJSDIR)/demo
# 通过 $(MAKE) -C 递归调用下层的 Makefile
$(TRAGET):$(OBJSDIR) main.o
$(MAKE) -C add
$(MAKE) -C sub
$(CC) -o $@ $(OBJSDIR)/*.o
main.o:%.o:%.c
$(CC) -c -o $(OBJSDIR)/$@ $< $(CFLAGS) -Iadd -Isub
$(OBJSDIR):
mkdir -p $(OBJSDIR)
clean:
$(RM) $(TRAGET) $(OBJSDIR)/*.o
add 目录下的 Makefile
OBJS = add.o all:$(OBJS) $(OBJS):%.o:%.c $(CC) -c -o $(OBJSDIR)/$@ $< $(CFLAGS)
sub 目录下的 Makefile
OBJS = sub.o all:$(OBJS) $(OBJS):%.o:%.c $(CC) -c -o $(OBJSDIR)/$@ $< $(CFLAGS)
测试编译
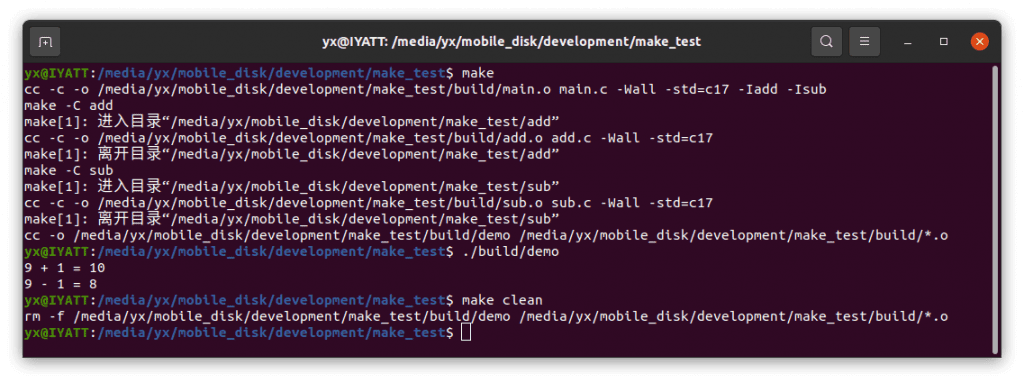
make 中的函数
在较大的工程中,经常需要一些匹配操作或者自动生成规则的功能,make 函数就派上用场了。
(一)获取匹配模式的文件名 – wildcard
这个函数的功能是查找当前目录下所有符合模式 pattern 的文件名,其返回值是以空格分割的所有符合模式 pattern 的文件名列表。格式如下
$(wildcard pattern)
如下,该模式下返回当前目录下所有扩展名为 .c 的文件的列表
$(wildcard *.c)
(二)模式替换 – patsubst
这个函数的功能是查找字符串 text 中按照空格分开的子串,将符合模式 pattern 的字符串替换为 replacement。pattern 中的模式可以使用通配符,% 代表 0~n 各字符,当 pattern 和 replacement 中都有 % 时,符合条件的字符被 replacement 中的替换。函数的返回值是替换后的新字符串。原型如下
$(patsubst pattern, replacement, text)
例如需要将 .c 文件替换为 .o 文件时可以使用
$(patsubst %.c, %.o, $(wildcard *.c))
(三)循环函数 – foreach
函数的功能为 foreach 将 list 字符串中一个空格隔开的字串,先传给临时变量 var,然后执行 text 表达式,text 表达式处理结束后输出,返回值为空格隔开的表达式 text 的执行结果。
这个函数的原型为
$(foreach var, list, text)
这里还是以前面的工程为例,然后重新写 Makefile 文件。项目结构回到开始的时候,如下
CFLAGS = -Wall -std=c17 -Iadd -Isub TARGET = demo DIRS = add sub . # 查找目录下所有扩展名为 .c 的文件 FILES = $(foreach dir, $(DIRS), $(wildcard $(dir)/*.c)) # 将扩展名由 .c 替换为 .o OBJS = $(patsubst %.c, %.o, $(FILES)) $(TARGET):$(OBJS) $(CC) -o $@ $^ $(CFLAGS) clean: $(RM) $(TARGET) $(OBJS)
