最近更新于 2024-05-05 14:18
2023.5.14 查到成绩了,一把过,分数为良好,也就是八十几分。自认为的话操作题的60分我是拿满了,扣分应该是选择题。我以为考场不提供草稿纸(实际可以),笔都没带,所以选择题中给代码问运行结果的(占大头),我也懒得去心算慢慢推,基本看一下就选,还有些问基础概念我不是很清楚的也是带着感觉选的,最终分数还是在能接受范围内。
希望看到本文的朋友们考试也能一把过!

1 发发恼骚
最近开始准备计算机二级 C 语言考试,刷题遇到的情况可折腾我了。平时我写 C 代码是规范了格式的,但是这个题目感觉是为了考到人而考人的感觉,题目的代码比较刁钻,谁搞开发像它这么写代码。不仅是格式乱,而且有些是 C 语言标准都没规定的写法,全看编译器怎么实现,还有些写法是故意让人不能直接看出结果而没有实际意义的,明明可以写得很清晰,但是非要写得混乱来考人。
这里我就总结一下一些可能遇到的情景,以考试要求的环境进行测试。
2 环境
Microsoft Visual C++ 2010 学习版
3 情景
下面的内容排布顺序并没有逻辑关系,只是题目遇到或者突然想到的情景就写下来
3.1 VC++2010 运行一闪而过
这个本身是正常的现象,程序运行结束了,为了运行它而创建的控制台窗口自然会关闭。为了不让它自动关闭,就得在关闭控制台窗口前阻塞。
就有两类思路,一类是程序内部阻塞,比如使用输入函数或者调用 pause 命令
(1)
#include <stdio.h>
int main()
{
getchar(); // 放在程序末尾
}按回车键结束
(2)
#include <stdlib.h>
int main()
{
system("pause"); // 放在程序末尾
}
另外一类思路是由 VC++2010 进行控制
(1)在 return 0 前面设置断点


(2)使用 VC++2010 提供的直接运行
点开项目属性
配置属性-链接器-系统-子系统,选控制台
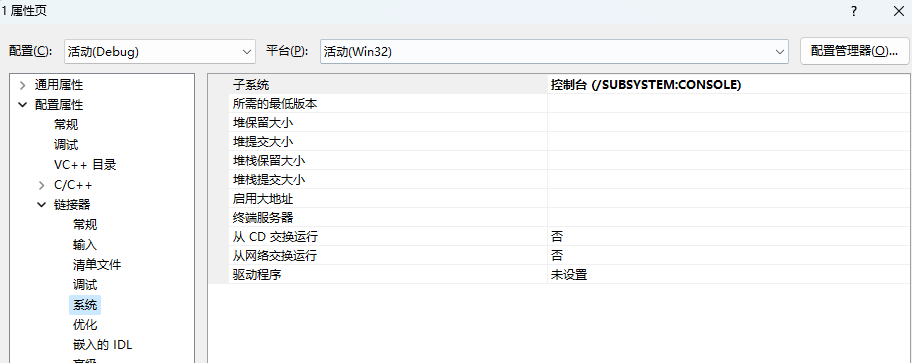
运行程序的时候按 Ctrl+F5(不调试直接运行),平时调试运行是按的 F5
考试的时候操作题的属性是已经设置成控制台的,也就是可以直接用 Ctrl+F5
这样运行会自动给你调用 pause 命令
计算机二级这个说实话调试不调试意义不大,就那么点代码,逻辑层次不会复杂。而且在二级这个水平上,真的会用调试功能的人有多少,如果不会用调试功能,那么直接运行和调试运行就没啥区别,不如怎么方便怎么来。
3.2 入口函数 main
三十多年前的 C89 就规定了是 int main,不要写 void main 了。考试题目可能出现 void main,但是考完后自己要知道不能这么写(软件开发按这个来,单片机开发例外)
3.3 gets
C11 标准中已经删除了 gets 函数,做开发的时候也不要用了。这个函数不会检查储存空间是否足够,你输入多少就会强行写入多少,可能会造成内存溢出
3.3.1 变量定义位置
C89 要求变量只能在头部位置定义,即在某个函数内定义变量,只能在最开头的位置,在定义变量的语句之前不能有其它执行语句。而 C99 取消了限制,从此之后的标准都没有限制,只要在使用变量之前定义了就可以。VC++6.0 以前用过,只能在头部定义,这个 VC++2010 依然只能在头部定义,这个我是有点无语,上一个标准都出了十年了还没支持这个特性(后面的我用过 2019 和 2022 可以)。
只能在头部定义下面这种情况就不支持
for (int i = 0; i < 10; ++i)只能写
int i; // 要放在头部,在定义变量位置的前面不能有其它逻辑执行语句
for (i = 0; i < 10; ++i)刚转过来用 VC++2010 练习时就遇到过定义位置不在头部导致的错误,莫名其妙了半天才反应过来
3.4 数据类型大小
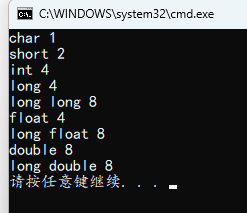
练习的时候我有遇到有题问 VC++6.0 下某些基本数据类型的大小,应该是老题目,我按 VC++2010 的选的答案没问题,至于是不是都一样我也不清楚了。之前用 VC++6.0 都是三年前大一上 C 语言课程的时候了,既然现在的 NCRE 2 要求的是 VC++2010,那就以它的情况来考虑总没错。
#include <stdio.h>
int main()
{
printf("char %u\n", sizeof(char));
printf("short %u\n", sizeof(short));
printf("int %u\n", sizeof(int));
printf("long %u\n", sizeof(long));
printf("long long %u\n", sizeof(long long));
printf("float %u\n", sizeof(float));
printf("long float %u\n", sizeof(long float));
printf("double %u\n", sizeof(double));
printf("long double %u\n", sizeof(long double));
}
3.5 if
3.5.1 控制范围
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
if (0)
a = 4;
b = 4;
printf("a=%d,b=%d\n", a, b);
}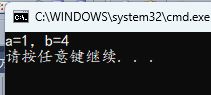
if 同行后面没有语句时,if 的下一行由 if 控制
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
if (0) a = 3; b = 3;
printf("a=%d,b=%d\n", a, b);
}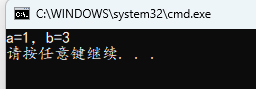
if 同行后有语句,第一个语句由 if 控制
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int c = 3;
if (0) a = 4;
b = 4;
c = 4;
printf("a=%d,b=%d,c=%d\n", a, b, c);
}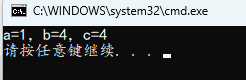
if 后有语句,下一行不由 if 控制
if 后第一个语句由 if 控制,无论排布格式
3.5.2 else 匹配
#include <stdio.h>
int main()
{
int i;
for (i = 0; i < 10; ++i)
if (i % 2 == 0)
if (i == 6)
printf("6 YES\n");
else
printf("偶数 %d\n", i);
else
printf("奇数 %d\n", i);
}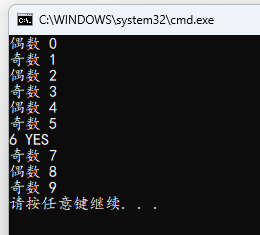
可以看出 else 默认会匹配当前作用域内最近的 if
我一般还是习惯都加上大括号,这样看起来会更清晰一些,只是考题喜欢上面那种格式,所以还是要清楚逻辑关系
#include <stdio.h>
int main()
{
int i;
for (i = 0; i < 10; ++i)
{
if (i % 2 == 0)
{
if (i == 6)
{
printf("6 YES\n");
}
else
{
printf("偶数 %d\n", i);
}
}
else
{
printf("奇数 %d\n", i);
}
}
}3.6 switch
#include <stdio.h>
int main()
{
int a = 1;
switch (a)
{
case 9:
printf("9\n");
case 1:
printf("1\n");
case 2:
printf("2\n");
case 3:
printf("3\n");
default:
printf("default\n");
}
}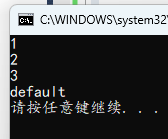
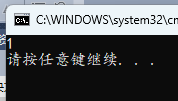
case 匹配项中没有添加 break,那么下一个 case 会接着执行,如果也没有 break,则再下一个接着执行……
#include <stdio.h>
int main()
{
int a = 1;
switch (a)
{
default:
printf("default\n");
break;
case 9:
printf("9\n");
break;
case 1:
printf("1\n");
break;
case 2:
printf("2\n");
break;
case 3:
printf("3\n");
break;
}
}
#include <stdio.h>
int main()
{
int a = 7;
switch (a)
{
default:
printf("default\n");
break;
case 9:
printf("9\n");
break;
case 1:
printf("1\n");
break;
case 2:
printf("2\n");
break;
case 3:
printf("3\n");
break;
}
}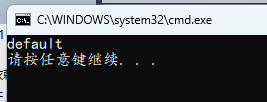
default 不管位置在哪里,都只有在 case 无法匹配到的时候才匹配 default
3.7 自增自减
#include <stdio.h>
int main()
{
int a = 10;
printf("%d\n", a++);
a = 10;
printf("%d\n", ++a);
a = 10;
printf("%d\n", a--);
a = 10;
printf("%d\n", --a);
}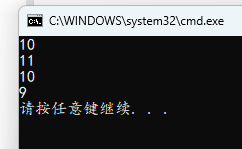
前增取自增后的值,后增取原值,自减操作性质类似
注意下面这个例子的情况在开发中不要使用,这个是 C 语言标准没有规定的,也就是实际上没有答案的。具体怎么处理看编译器,这里的情况仅在考试要求的环境的前提下
#include <stdio.h>
int main()
{
int a = 10;
int b = ++a + ++a;
printf("%d\n", b);
a = 10;
b = ++a + a++;
printf("%d\n", b);
a = 10;
b = a++ + ++a;
printf("%d\n", b);
a = 10;
b = a++ + a++;
printf("%d\n", b);
a = 10;
printf("%d %d\n", ++a, ++a);
a = 10;
printf("%d %d\n", ++a, a++);
a = 10;
printf("%d %d\n", a++, ++a);
a = 10;
printf("%d %d\n", a++, a++);
}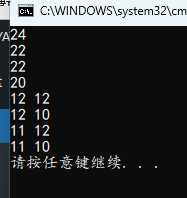
前增加前增,等于两次自增后的值相加
前增和后增相加,等于一次自增后的值相加(前增有效,后增无效)
后增加后增,等于原值相加
先不管加法,只看自增,如果是前增就有效,如果是后增就无效,将自增后的值相加
两次前增各自的取值,都等于两次自增后的值
前增和后增各自取值,前增取两次自增后的值,后增取原值
后增和前增各自取值,后增取一次自增后的值,前增取两次自增后的值
两次后增各自取值,第一个等于自增后的值,后一个等于原值
前增的取值是前增和后增都有效的累计结果,后增的取值等于右边自增一次后(如果有的话)的结果
3.8 = 和 , 优先级
#include <stdio.h>
int main()
{
int a = 10;
int b;
b = ++a, ++a;
printf("%d\n", b);
a = 10;
b = ++a, a++;
printf("%d\n", b);
a = 10;
b = a++, ++a;
printf("%d\n", b);
a = 10;
b = a++, a++;
printf("%d\n", b);
}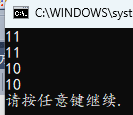
赋值运算的优先级高于逗号运算符,所以逗号运算发左边第一个表达式的值会用于赋值
3.9 逗号运算符顺序
#include <stdio.h>
int main()
{
int a = 10;
int b;
b = (++a, ++a);
printf("%d\n", b);
a = 10;
b = (++a, a++);
printf("%d\n", b);
a = 10;
b = (a++, ++a);
printf("%d\n", b);
a = 10;
b = (a++, a++);
printf("%d\n", b);
}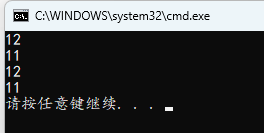
从左往右依次进行,这里不管左边是前增还是后增,右边使用的值都是左边进行一次自增后的值
3.10 逻辑运算
进行逻辑运算时,先需要将十进制转为二进制。
举个例子,100 转二进制
100\div2=50\cdot\cdot\cdot\cdot\cdot\ \cdot0
50\div2=25\cdot\cdot\cdot\cdot\cdot\ \cdot0
25\div2=12\cdot\cdot\cdot\cdot\cdot\ \cdot1
12\div2=6\cdot\cdot\cdot\cdot\cdot\ \cdot0
6\div2=3\cdot\cdot\cdot\cdot\cdot\ \cdot0
3\div2=1\cdot\cdot\cdot\cdot\cdot\ \cdot1
取最后一次的商再接上从后往前的余数,即为 1100100
逻辑运算结果要转回十进制
1100100(二进制) = 1\times 2^6+1\times 2^5+0\times 2^4+0\times 2^3+1\times 2^2+0\times 2^1+0\times 2^0(十进制)
3.10.1 按位与 &
01100100 & 00101011,对位都为 1 才为 1,否则为 0,结果为 00100000
3.10.2 按位或 |
01100100 | 00101011,对位有一个为 1 即为 1,都为 0 才为 0,结果为 01101111
3.10.3 按位异或 ^
01100100 ^ 00101011,对位不同时为 1,否则为 0,结果为 01001111
3.10.4 取反运算符 ~
~01100100 取反 1 变 0,0 变 1,结果为 10011011
3.10.5 左移运算符 << 和 右移运算符 >>
正数原码:将数字按绝对大小转为二进制,比如 10 的原码 00001010(8位)
负数原码:将数字按绝对大小转为二进制,最高位取 1,-10 的原码 10001010
正数反码:与原码相同
负数反码:原码除符号位都取反,-10 反码 11110101
正数补码:与原码相同
负数补码:反码加一,-10 补码 11110110
#include <stdio.h>
int main()
{
int a = 10;
printf("%u\n", a);
a = -10;
a = ~a;
printf("%u\n", a);
}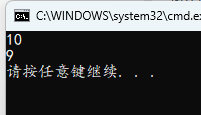
这里 int 是 4 字节,即 32 位数。%d 是按照有符号数的规则来解读,而 %u 则是按照无符号数来解读,即直接当作正数,正数不管哪种码都是绝对值的二进制,方便分析二进制的绝对数值。
10 的补码是 0000…1010(32位),-10 的补码是 1111…0110(32位),然后我这里取反了为 0000…1001,直接按无符号数解读就是 1\times2^3+1=9,结果符合上面的运行结果,即 C 语言底层实现是用的补码
#include <stdio.h>
int main()
{
int a = 10;
a <<= 3;
printf("%u\n", a);
a = -10;
a <<= 3;
a = ~a;
printf("%u\n", a);
}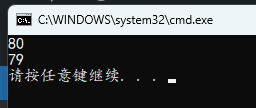
10 的补码为 0000…1010(32位),左移 3 位,低位用 0 填充,为 0000…1010000,对应十进制为 1\times2^6+1\times2^4=80,符合运行结果
-10 的补码为 1111…0110(32位),左移 3 位,高位抛弃,低位 0 填充,为 1111…0110000,取反为 0000…1001111,对应十进制为2^6+2^3+2^2+2+1=79,符合运行结果
#include <stdio.h>
int main()
{
int a = 10;
a >>= 2;
printf("%u\n", a);
a = -10;
a >>= 2;
a = ~a;
printf("%u\n", a);
}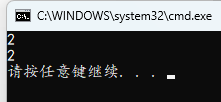
10 的补码为 0000…1010(32位),右移 2 位,高位为 0,用 0 填充,右边抛弃,为 0000…0010,对应十进制为 2,符合运行结果
-10 的补码为 1111…0110(32位),右移 2 位,高位为 1,用 1 填充,右边抛弃,为 1111…1101,取反为 0000.。。0010,对应十进制为 2,符合运行结果
上面是从原理层面进行理解,正数的位移实际上并不需要转为二进制进行处理。先举个例子,十进制的 10000 按照十进制右移 2 位,就变成了 100,按照十进制左移两位就变成 1000000,位移 n 位就是乘以(左)/除以(右)10 的 n 次方。放到二进制层面处理就是 2 的 n 次方,100 左移(默认二进制)2 位就是 100\times2^2,右移 2 位就是 100\div2^2
至于为什么要使用补码表示数字?这是因为计算机 CPU 只有加法计算器,补码可以将其它运算转为加法和位移来处理。比如减法 10 – 9 = 10 + (-9) = 00001010 + 11110111 = 00000001 = 1
3.11 整数数组初始化
#include <stdio.h>
#define C 4
void print1(int num[], int c)
{
int i;
for (i = 0; i < c; ++i)
{
printf("%d ", num[i]);
}
printf("\n--------------------\n");
}
void print2(int r, int num[][C])
{
int i, j;
for (i = 0; i < r; ++i)
{
for (j = 0; j < C; ++j)
{
printf("%d ", num[i][j]);
}
printf("\n");
}
printf("--------------------\n");
}
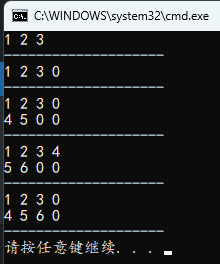
int main()
{
int num1[] = {1, 2, 3};
int num2[4] = {1, 2, 3};
//int num3[] = {{1, 2, 3}}; // 错误
int num4[][C] = {{1, 2, 3}, 4, 5};
//int num5[][C] = {{1, 2, 3, 4, 5}, 6, 7, 8}; // 初始化列数不匹配
//int num6[2][C] = {{1, 2}, {3, 4}, {5, 6}}; // 初始化行数不匹配
int num7[][C] = {1, 2, 3, 4, {5, 6}};
//int num8[][C] = {1, 2, 3, {4, 5, 6}}; // 初始化列数不匹配
int num9[][C] = {{1, 2, 3}, {4, 5, 6}};
print1(num1, 3);
print1(num2, 4);
print2(2, num4);
print2(2, num7);
print2(2, num9);
}
3.12 字符串指针和字符数组的初始化及赋值
#include <stdio.h>
void print(char *s)
{
printf("%s\n", s);
}
int main()
{
char *s1 = "abcd";
char *s2 = {"abcd"};
char s3[] = "abcd";
char s4[] = {"abcd"};
//s1 = {"1234"}; // 错误
s2 = "1234567890";
//s3 = "1234"; // 错误
//s4 = {"1234"}; // 错误
print(s1);
print(s2);
print(s3);
print(s4);
}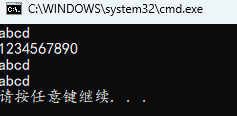
字符串指针和字符数组初始化可以加大括号也可以不加。字符串数组初始化后,后面可以修改指向(但不能用大括号),指向地址变了,则值可能会改变。而字符数组就不能使用直接赋值字符串的方式修改了,要么自己实现遍历,一个字符一个字符的修改,或者使用标准库的字符串/内存拷贝函数之类的进行字符串赋值。
3.13 函数指针
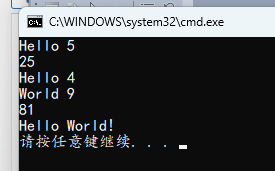
#include <stdio.h>
// 基本数据类型的返回值
int func1(int x)
{
printf("Hello %d\n", x);
return x * x;
}
// 指针类型的返回值
int *func2(int *x)
{
printf("World %d\n", *x);
*x *= *x;
return x;
}
// 无返回值
void func3()
{
printf("Hello World!\n");
}
int main()
{
int (*f1)(int x);
int r1;
int *(*f2)(int *x);
int *r2;
int x2;
void (*f3)();
f1 = func1; // 指向函数
r1 = (*f1)(5);
printf("%d\n", r1);
f1 = &func1; // 指向函数
(*f1)(4);
f2 = func2;
x2 = 9;
r2 = (*f2)(&x2);
printf("%d\n", *r2);
f3 = func3;
f3();
}
3.14 全局变量和局部变量同名
这个在开发中是不建议的,容易混淆,增大写出 BUG 的机率。
#include <stdio.h>
int a = 10;
void func(int a)
{
printf("%d\n", a);
}
int main()
{
printf("%d\n", a);
func(20);
{ // 大括号限制作用域,下面定义的变量仅在内部有效
int a =30;
printf("%d\n", a);
}
printf("%d\n", a);
}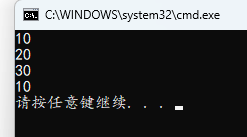
可以看出,全局变量和局部变量同名时,使用的是局部变量,只有在某个作用域内不存在同名居于变量时才使用全局变量
3.15 格式注意
3.15.1 浮点数赋值
我在使用某软件练习的时候,浮点数我赋值 0 给我判错,而答案是 0.0。实际编译器都会进行 0 到 0.0 的隐式转换,所以写 0 本身也没啥问题。就是不知道二级考试的时候能不能直接写 0,稳妥点还是写成浮点数吧。
3.15.2 代码空格格式
有次练习,填空题中我写的 s / N,给我判错,答案是 s/N,没错就是空格。不清楚考试怎么批改,还是学题目挤一坨的风格应该比较稳妥。
3.16 带参宏定义
#include <stdio.h>
#define FUN(x) x * 9
int main()
{
printf("%d\n", FUN(7 + 1));
}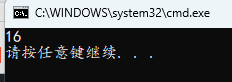
上面的例子有可能会被当作 printf("%d\n", 8 * 9) 来考虑,但宏替换是在编译前的预处理阶段进行,只是单纯的文本替换,不会计算值,所以实际是 printf("%d\n", 7 + 1 * 9)
3.17 赋值表达式的取值
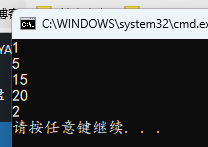
#include <stdio.h>
int main()
{
int a = 10;
printf("%d\n", a = 1);
a = 10;
printf("%d\n", a -= 5);
a = 10;
printf("%d\n", a += 5);
a = 10;
printf("%d\n", a *= 2);
a = 10;
printf("%d\n", a /= 5);
}
#include <stdio.h>
int func(int *n)
{
return *n - 5;
}
int main()
{
int n = 20;
while (n = func(&n))
{
printf("A %d\n", n);
}
n = 20;
while ((n = func(&n)) != 5)
{
printf("B %d\n", n);
}
}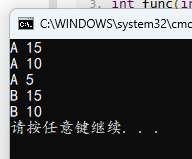
可见赋值语句的值就等于赋值以后的值
3.18 标识符命名
就是像变量名,函数名这些命名,其实很多语言的规则都是这一套
命名可以使用大小写字母,数字和下划线,名字第一个字符不能用数字,不能使用语言本身已用的关键词
// 正确的
int abcd_4242;
int _das;
int d_dsd;
int s89;
int a;
int _;
int For;
int IF;
// 错误的
int 8dad;
int 988_f;
int 1_;
int for;
int if;
int else;3.19 二维数组指针层面理解
3.19.1 理解
#include <stdio.h>
int main()
{
int a[4][4];
int i, j;
int count = 0;
char *s[] = {"1234", "abcd", "09jh"};
for (i = 0; i < 4; ++i) // 初始化数组
{
for (j = 0; j < 4; ++j)
{
a[i][j] = count++;
}
}
for (i = 0; i < 4; ++i) // 遍历数组
{
for (j = 0; j < 4; ++j)
{
printf("%d\t", *(*(a + i) + j)); // a[i][j]
}
printf("\n");
}
printf("------------------------------\n");
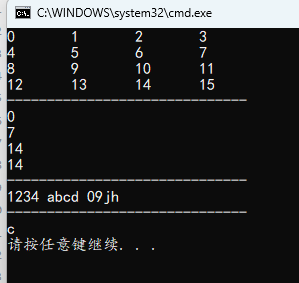
printf("%d\n", **a); // a[0][0] = *(*(a + 0) + 0)
printf("%d\n", *(*(a + 1) + 3)); // a[1][3]
printf("%d\n", *(*a + 14)); // 14 / 4 = 3......2,即 a[3][2]
printf("%d\n", *(*a + 4 * 3 + 2));
printf("------------------------------\n");
for (i = 0; i < 3; ++i)
{
printf("%s ", *(s + i)); // s[i]
}
printf("\n------------------------------\n");
printf("%c\n", *(*(s + 1) + 2)); // s[1][2]: 'c’
}
假如有一个数组 a[M][N],我要取 m 行 n 列的数据(0 ≤ m < M, 0 ≤ n < N)
- 方法一:a[m][n]
- 方法二:*(*(a + m) + n)
- 方法三:*(*a + N * m + n)
二维数组实际就是个二级指针,一级指针保存的是每行行首地址,比如 *a 就是 0 行的首个元素的地址。**a 就把 0 行首个元素取出来,即 a[0][0]
如果要取 a[m][n],则先获取第 m 行的首元素地址 *(a + m),那么第 m 行第 n 列的地址就是 *(a + m) + n,取这个地址的值就是 *(*(a + m) + n),即方法二的原理
二维数组分配的内存是连续的,也就是说只要知道第 0 行第 0 列的地址,就可以通过偏移值获取所有元素。*a 就是第 0 行首元素的地址,那么第 m 行第 n 列的地址就是 *a + 数组列数N * 元素所在行数m + 元素所在列数n,即 *a + N * m + n,取这个地址的值就是 *(*a + N * m + n),即方法三的原理
3.19.2 传参
#include <stdio.h>
void func1(int a[])
{
printf("一维数组传参 %u\n", sizeof(a));
}
void func2(int a[][4])
{
printf("二维数组传参 %u\n", sizeof(a));
}
int main()
{
int a[4];
int b[4][4];
printf("一维数组 %u\n", sizeof(a));
func1(a);
printf("二维数组 %u\n", sizeof(b));
func2(b);
}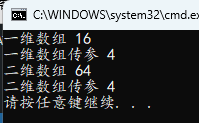
实参数组传给函数,函数内部的形参实际就是指针了,获取到的大小也是对应类型指针的大小,所以通常函数传参还要传入数组的大小才能正常使用
3.20 静态变量使用
#include <stdio.h>
int func(int x)
{
static int a = 0;
a += x;
return a;
}
int main()
{
int b = func(3) + func(5);
printf("%d\n", b);
b = func(9);
printf("%d\n", b);
}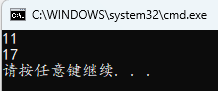
静态变量内存分配在全局区,和全局变量一样,如果不初始化,也会默认初始化为 0。上面例子中的全局变量在首次使用时被初始化为零,在 func 函数运行结束后内存也不会被释放,下次调用 func 函数,静态变量不会再赋值为 0,而是继续使用上一次执行结束后的值
3.21 连续赋值
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
a = b = c = d = 5;
printf("%d %d %d %d\n", a, b, c, d);
}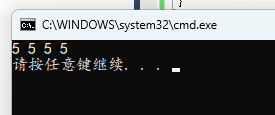
连续赋值从右往左进行
3.22 文件读写
3.22.1 fopen 模式
r
以只读方式打开文件,该文件必须存在。
r+
以读/写方式打开文件,该文件必须存在。
rb+
以读/写方式打开一个二进制文件,只允许读/写数据。
rt+
以读/写方式打开一个文本文件,允许读和写。
w
打开只写文件,若文件存在则文件长度清为零,即该文件内容会消失;若文件不存在则创建该文件。
w+
打开可读/写文件,若文件存在则文件长度清为零,即该文件内容会消失;若文件不存在则创建该文件。
a
以附加的方式打开只写文件。若文件不存在,则会创建该文件;如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(EOF 符保留)。
a+
以附加方式打开可读/写的文件。若文件不存在,则会创建该文件,如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(EOF符不保留)。
wb
以只写方式打开或新建一个二进制文件,只允许写数据。
wb+
以读/写方式打开或新建一个二进制文件,允许读和写。
wt+
以读/写方式打开或新建一个文本文件,允许读和写。
at+
以读/写方式打开一个文本文件,允许读或在文本末追加数据。
ab+
以读/写方式打开一个二进制文件,允许读或在文件末追加数据。
3.22.2 实例
// 微软搞些莫名其妙的安全函数真的无语
// 标准库函数正确使用也是安全的
// 安全函数没有正确使用也没用
#define _CRT_SECURE_NO_WARNINGS // 关闭不使用安全函数的警告
#include <stdio.h>
#include <stdlib.h> // exit
#include <string.h> // memset
#define TEXT_FILE "text.txt"
#define BIN_FILE "bin.txt"
// 创建文本文件、写入数据
void func1()
{
FILE *fp = fopen(TEXT_FILE, "w");
if (!fp)
{
perror("func1 文件打开失败!\n");
exit(1);
}
if (fputc('A', fp) == EOF) // 写入字符
{
perror("func1 写入字符失败!\n");
exit(1);
}
fputs("\n123abc\n", fp); // 写入字符串
fprintf(fp, "%s %d", "hello", 10); // 格式化写入
fclose(fp); // 关闭文件
}
// 读取文本文件
void func2()
{
char s1[32], s2[32];
int i = 0;
FILE *fp = fopen(TEXT_FILE, "r");
if (!fp)
{
perror("func2 文件打开失败!\n");
exit(2);
}
putchar(fgetc(fp)); // 读取一个字符
putchar(fgetc(fp)); // 读取末尾的换行符
memset(s1, 0, sizeof(s1)); // 初始化字符串数组
fgets(s1, sizeof(s1), fp); // 读取字符串
printf("%s", s1);
memset(s2, 0, sizeof(s2));
fscanf(fp, "%s %d", s2, &i); // 格式化读取
printf("%s %d\n", s2, i);
fclose(fp);
}
typedef struct
{
char name[12];
int age;
} person;
// 创建文件、写入二进制数据
void func3()
{
person p1[3] =
{
{"小明", 20},
{"小强", 18},
{"小红", 19}
};
FILE *fp = fopen(BIN_FILE, "wb");
if (!fp)
{
perror("func3 打开文件失败!\n");
exit(3);
}
fwrite(p1,
sizeof(person), // 单个结构体的大小
3, // 结构体实例个数
fp);
fclose(fp);
}
// 读取二进制数据
void func4()
{
int i;
person p2[3] = {0};
FILE *fp = fopen(BIN_FILE, "rb");
if (!fp)
{
perror("func3 打开文件失败!\n");
exit(4);
}
fread(p2, sizeof(person), 3, fp);
for (i = 0; i < 3; ++i)
{
printf("%s %d\n", p2[i].name, p2[i].age);
}
fclose(fp);
}
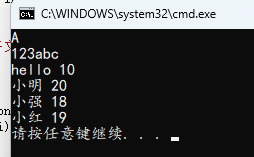
int main()
{
func1();
func2();
func3();
func4();
return 0;
}
3.23 结构体定义及实例化
// 1
struct A // 定义结构体 A
{
int a;
int b;
};
struct A a; // 定义一个实例 a
// 2
struct B // 定义结构体 B 的同时,定义了实例 b1, b2
{
int a;
int b;
} b1, b2;
struct B b3;
// 3
struct // 定义了两个实例 c1, c2,结构体没名字后续不能再定义实例
{
int a;
int b;
} c1, c2;
// 4
typedef struct // 定义结构体,并为结构体取别名为 D
{
int a;
int b;
} D;
D d1, d2; // 定义实例 d1, d2
// 5
typedef struct E // 定义结构体 E,并为 struct E 取别名为 E
{
int a;
int b;
} E;
struct E e1; // 通过结构体名字定义实例
E e2; // 通过别名定义实例C 语言中如果不取别名,定义结构体实例时必须加上关键词 struct,即 struct 结构体名 实例名
取别名可以将 struct {} 或者 struct 结构体名 {} 整体设为一个名字使用
补充:C++ 中的 struct 和 C 中的不同,C++ 中的 struct 本质上是一个类,只是默认权限为 public(公开),而 class 的默认权限为 private(私有)。C++ 中定义结构体实例时不需要加上 struct 关键词,可以直接使用结构体名定义实例,即 结构体名 实例名
4 常见算法时间复杂度
- 线性搜索(Linear Search):时间复杂度为 O(n)
- 二分查找(Binary Search):时间复杂度为 O(log n),元素必须已排序
- 冒泡排序(Bubble Sort):时间复杂度为 O(n^2)
- 插入排序(Insertion Sort):时间复杂度为 O(n^2)
- 快速排序(Quick Sort):时间复杂度为 O(n log n)
- 归并排序(Merge Sort):时间复杂度为 O(n log n)
- 堆排序(Heap Sort):时间复杂度为 O(n log n)
- 选择排序(Selection Sort):时间复杂度为 O(n^2)